[Back-To-Basic] - Zero Copy
数据传输-常规做法
考虑从文件中读取数据并通过网络将数据传输到另一个程序的场景,比如,提供静态内容的Web应用程序、FTP服务器、邮件服务器等。常规实现就是从磁盘读取文件内容到一个buffer,然后通过网卡发送,代码实现也很简单:
1 | File.read(fileDesc, buf, len); |
 |
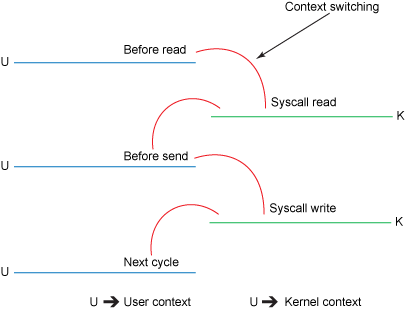 |
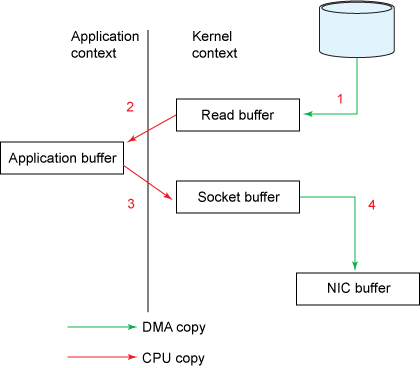
然而,如上面两图所示,实际上发生了4次拷贝(copy),4次上下文切换(context switch)和2次系统调用(system call):
read()该系统调用导致从用户模式到内核模式的上下文切换。在内部发出sys_read()(或等效函数)以从文件中读取数据。第一个副本由直接内存访问 (DMA) 引擎执行,该引擎从磁盘读取文件内容并将它们存储到内核地址空间缓冲区中(Read buffer)。- 请求的数据量从读取缓冲区复制到用户缓冲区(
Application buffer),然后read()调用返回。调用的返回导致另一个上下文从内核切换回用户模式。现在数据存储在用户地址空间缓冲区中。 send()套接字调用导致上下文从用户模式切换到内核模式。执行第三次复制,将数据再次放入内核地址空间缓冲区。不过这一次,数据被放入另一个缓冲区(Socket buffer),该缓冲区与目标套接字相关联。send()系统调用返回,创建第四次上下文切换。独立且异步地,当DMA引擎将数据从内核缓冲区传递到协议引擎时(NIC buffer),会发生第四次复制。
上述4个步骤,每个步骤会有一次拷贝,一次上下文切换,步骤1,3有一次系统调用
Zero Copy初步
上面流程可以看到,应用程序除了缓存数据并将其传输回套接字缓冲区外什么都不做。相反,数据可以直接从读取缓冲区传输到套接字缓冲区。 Java的transferTo,C/C++的sendfile方法可以做到这一点。
1 | public void transferTo(long position, long count, WritableByteChannel target); |
1 |
|
 |
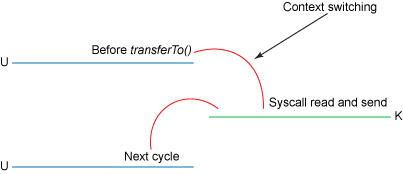 |
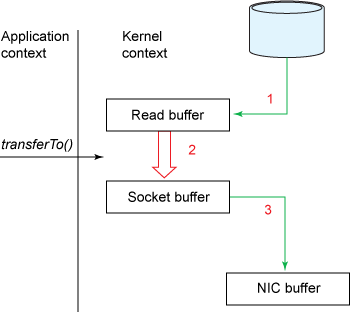
以Java的transferTo为例,上述流程可以被优化为2步:
transferTo/sendFile方法让文件内容被DMA引擎复制到读取缓冲区中。然后数据被内核复制到与输出套接字关联的内核缓冲区中。- 第三次复制发生在DMA引擎将数据从内核套接字缓冲区传递到协议引擎时。
Zero Copy最终形态
上述优化将上下文切换的次数从四个减少到两个,并将数据拷贝的数量从四个减少到三个(只有一个涉及CPU)。如果底层网络接口卡支持**gather**操作,可以进一步减少内核所做的数据重复。在Linux内核2.4及更高版本中,修改了套接字缓冲区描述符以适配此要求。这种方法不仅减少了多次上下文切换,而且消除了需要CPU 参与的重复数据拷贝。 用户端的用法仍然保持不变,但内部结构发生了变化:

transferTo/sendFile方法导致文件内容被DMA引擎复制到内核缓冲区中- 没有数据被复制到套接字缓冲区中。相反,只有包含有关数据位置和长度信息的描述符才会附加到套接字缓冲区。DMA引擎将数据直接从内核缓冲区传递到协议引擎,从而消除了剩余的最终CPU拷贝
上述2个步骤,每个步骤会有一次拷贝(DMA),一次系统调用,总共两次拷贝,两次系统调用!