Delta Lake: HighPerformance ACID Table Storage over Cloud Object Stores
What id Delta Lake
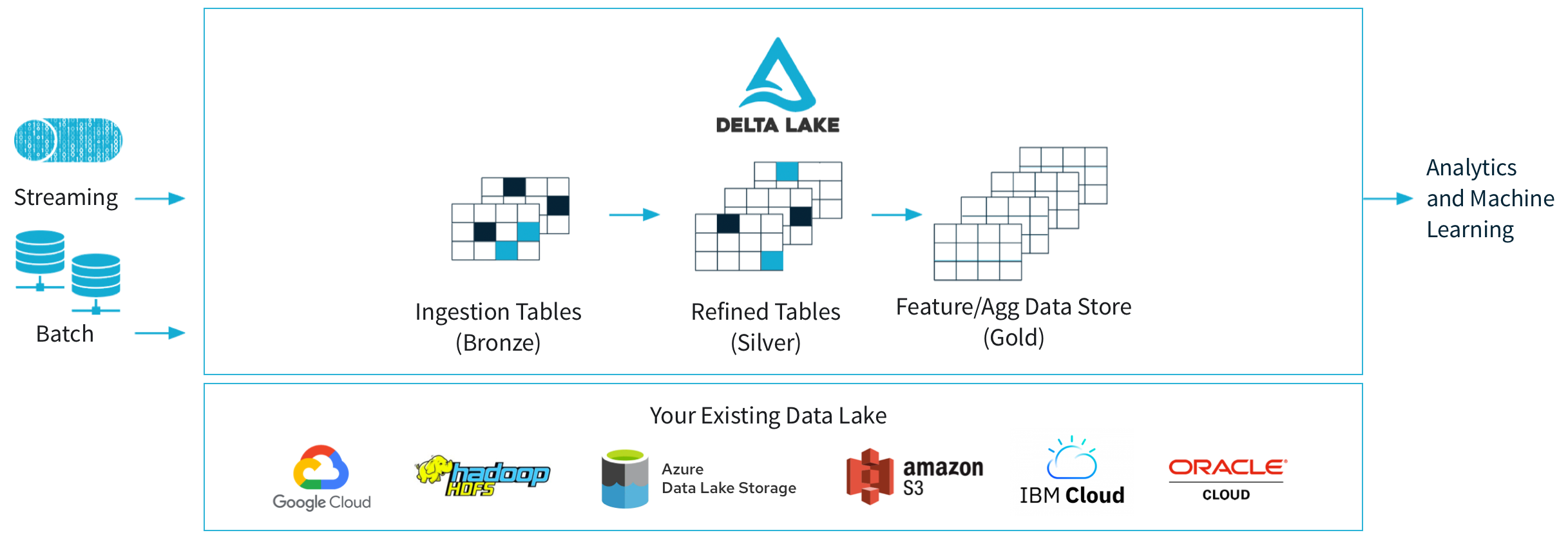
Delta Lake是一个基于云对象存储的开源的,ACID表存储层(表格式),它最初是由Databricks开发。Delta Lake表可以被Spark,Hive,Presto,Redshift,Trino等计算引擎读写,它每天处理Databricks客户们的EB级的数据,数十亿个对象(对象存储系统)。Delta Lake使用WAL,以ACID的方式维护哪些对象是Delta表的一部分的信息,表数据使用Parquet编码存储在对象存储中,其元数据以transaction log的形式存储在底层的对象存储中,并借助对象存储系统实现了OCC,这样就不需要一个服务(比如,HiveMetaStore)来维护Delta表的状态,用户只需在运行查询时拉起服务实例,即可享受单独扩展计算和存储的好处。
除了ACID事务,Delta Lake还提供了如下传统数据湖没有的特性:
- ACID 读写Delta表时提供ACID事务保障
- Time travel 用户可以查询某个时间点的快照,或者回滚对齐数据错误的更新
- UPSERT, DELETE and MERGE operations 有效地更新相关对象以实现更新归档数据和合规工作流(比如,GDPR)
- Efficient streaming I/O 流式作业低延迟地写入小对象到表中,然后事务性合并它们为更大的对象来提供性能。快速“tailing”新读入表中新增数据,这样作业可以将一个Delta表作为一个消息队列
- Caching Delta表的数据和log都是immutable的,可以缓存在计算节点的local SSD Cache中
- Data layout optimization 自动优化服务做compaction,clustering(比如,Z-order)提升查询性能
- Schema evolution 当Schema发送变更时,依然可以读取老的Parquet文件
- Audit logging 基于其transaction log来实现审计日志
Why Delta Lake
云对象存储系统,比如AWS S3和Azure Storage,除了具有云服务的传统优势,如按需付费、规模经济、专家管理等,还让用户可以单独扩展存储与计算资源;所以现在越来越多的组织使用云对象存储系统,存储和管理在其数据仓库和数据湖中的大量结构化数据集。一些开源和商业的大数据系统(Apache Spark,Presto,Redshift,BigQuery)支持读写在云对象存储系统中的这样的开放,列式数据格式文件(比如,Parquet,ORC),在云对象存储上存储关系型数据集最常见的形式也是Parquet/ORC这样的列式文件,每一个表都是被存储为一个Parquet/ORC文件集合(大量,甚至海量的对象)。虽然可以通过分区保证性能,但是对于大的数据集和复杂的workload,也带来了正确性和性能上的挑战:
- 多对象的更新是非原子的,查询之间没有隔离,一个query正在更新多个对象,它只能单独更新每个对象,让另一个query可能会读到部分更新,而且回滚困难,因为如果更新query崩溃,表将处于损坏状态。
- 对有大量对象的大表的元数据操作开销大,读取对象存储系统中每个Parquet文件到footer到统计数据(比如,min/max)造成在查询规划阶段data skipping check的时间比实际的查询时间执行的时间还长
- 大部分企业的数据集会持续更新,还要满足GPDR合规需求,以及内部错误数据修正,所以需要支持原子写和全表更新
- 对象存储是基于KV Store,cross key一致性没有保证,其性能特征也与传统的分布式文件系统不同
所以Databricks开发了Delta Lake,在享受云对象存储的弹性,高可用和低价的同时,提供统一的Table语义,ACID支持,支持多种计算引擎读写,比如,Spark,Presto,BigQuery
Delta Lake Design Consideration
对象存储的特征与挑战
对象存储API
对象存储系统让用户创建若干个桶(bucket)来存储数据,每个桶可以存多个对象,最大可以存储TB级的数据(S3是5TB),每个对象都是用一个字符串key来标识。对象存储API有如下特征:
- key通常使用文件系统路径来建模(比如,warehouse/table1/part1.parquet),但是与文件系统不同的是云对象存储的rename操作要重很多
- 云对象存储也提供元数据API,以S3的LIST为例,它会按照字典序list一个bucket中的对象,进而可以list某个字符串前缀,比如warehouse/table1/,来list某个“目录”的对象,但是每次调用只能返回1000个keys,且需要几十到几百毫秒
- 支持按照byte范围读取数据,比如读取一个大对象的10,000 - 20,000的数据
- 更新一个对象需要立即rewrite整个对象,不过是原子的
对象存储一致性特点
对象存储没有across-keys一致性保证,以最流行的对象存储S3为例,S3只保证最终一致性,客户端在写操作时上传一个对象,其它客户端不保证立即能list或者读到该对象,更新一个对象亦如此,甚至这个客户端本身不保证能看到新的对象。S3的客户端提供read-after-write一致性保证,PUT之后的GET会返回新的对象,但是如果在PUT某个新key之前发起过对该key的GET请求,那后续的GET请求会在一段时间内无法读取到新的对象。S3的PUT之后的LIST也无法保证能返回新的对象。虽然Azure Storage,GCS有强一致性保证,但是也缺乏across-keys原子操作。
对象存储的性能特征
每次读需要少5-10ms的基础延迟,然后读取速率约为50-100MB/s,所以每次最好读取250KB到1MB来获得峰值到吞吐(5ms * 50MB/s,10ms * 100MB/s),同时可以增加读的并行获充分利用网络带宽,比如10Gbps的带宽,并行可以为8-10。对象存储的性能特征给表存储带来了一些启示:
- 让经常访问的数据按顺序放置在一起,这通常会导致选择列式数据格式
- 对象大小要适中,因为对象的更新需要完全重写
- 尽量避免LIST操作,让这些操作按照字母序执行
表存储的业界方案
- Directories of Files
按照“目录”(与文件系统不同,对象存储中没有实际的目录,只是通过类似目录路径的字符串keys来建模)存放表数据,对于分区表可以按照分区“目录”存放。比如,mytable/date=2020-01-01/obj1,mytable/date=2020-01-01/obj2是分区2020-01-01的数据,mytable/date=2020-01-02/obj1存放分区2020-01-02的数据。这种将表建模成一堆对象的方案最初源自Apache Hive on HDFS,表可以被多种工具访问不需要额外的数据存储或系统,但是在云对象存储系统上有一致性和性能挑战:
- 没有跨多个对象的一致性,需要写或更新多个对象的事务有部分写被其它客户端读到的风险,事务失败数据可能处于损坏状态
- 最终一致性,即使事务成功了,有的客户端可能只看到部分更新的对象
- 低性能,查询规划时需要LIST相关分区的目录,然后读取每个文件的统计信息(比如,读取Parquet文件的footer)
- 没有管理功能,没有表版本,审计日志等数仓管理功能
- 定制存储引擎
以Snowflake为代表的云数据仓库在一个单独的,强一致的服务中管理元数据,实现了元数据高效的元数据存储,搜索,更新等。但是这种方案的缺点时:
- 所有的I/O操作需要与元数据服务交互,增加了资源开销,降低了性能和可用性
- 不是类似Parquet一样开放的数据格式,开发外部引擎connectors时需要更多的工作量
- 专有元数据服务将用户与特定vendor绑定,无法像直接访问对象存储的方案一样可以一直使用不同的技术
Hive ACID借助HiveMetastore,在HDFS或对象存储上也实现了类似方案,但是也会遇到性能问题。
这里我觉得是Databricks有些夹带私货,元数据放在一个高可用,高性能和可扩展的元数据服务中(比如,Snowflake的cloud service层)性能比放在云对象存储系统中反而有优势,而且S3不支持put-if-absent,也需要外部服务提供lock支持。
- 元数据存储在对象存储中
Delta Lake直接在云对象存储中存储一个事物日志和元数据,使用对象存储上的一组协议来实现串行化,表中的数据用Parquet格式存储,与之类似的还有Apache Iceberg和Apache Hudi。
Delta Lake Deep Dive
Storage Format
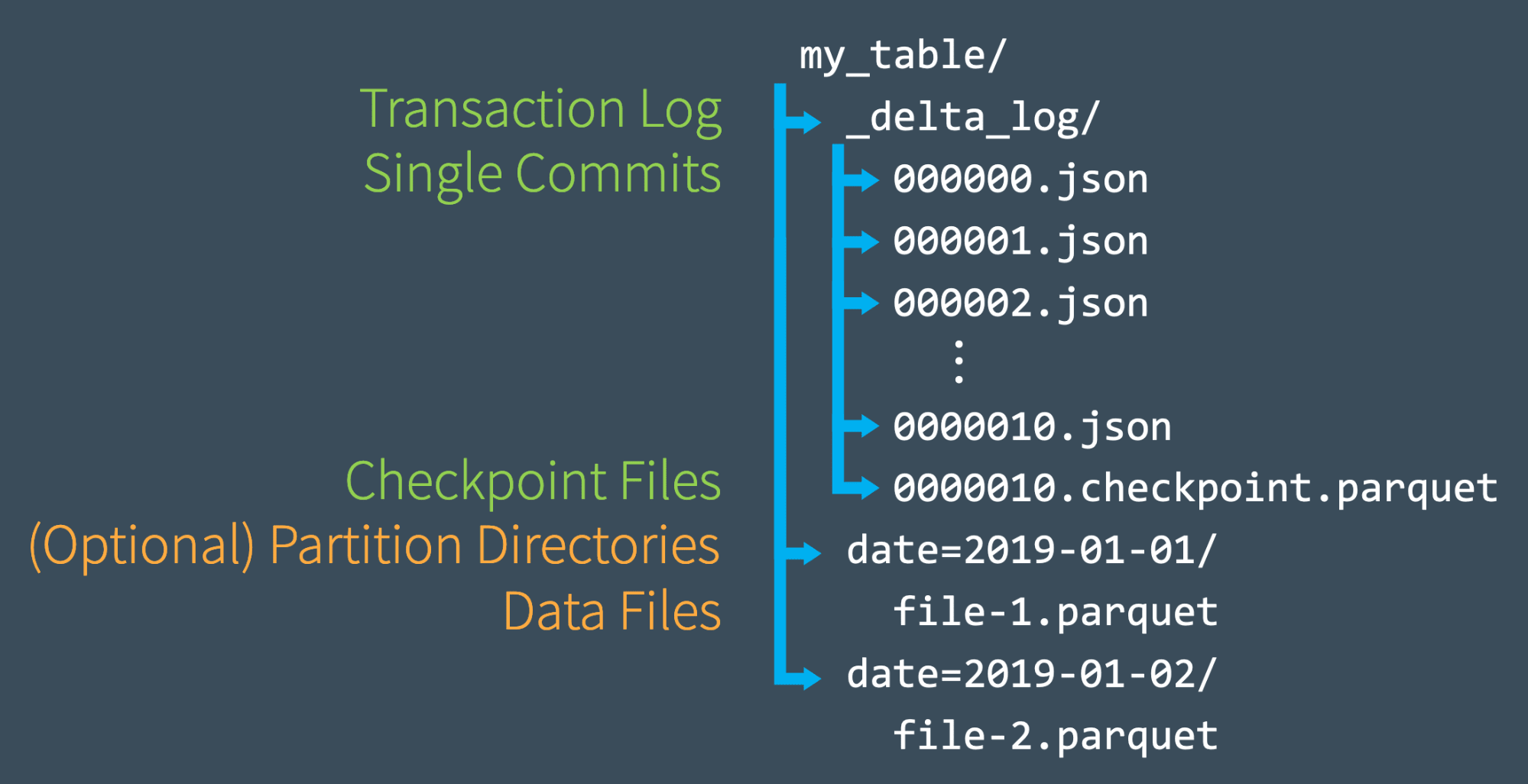
从上图可以看出,一个Delta Lake表主要由三部分组成:数据文件,事物日志,Checkpoint文件。
- 数据文件,可以按照分区存储在不同的分区目录中,Parquet格式
- 事物日志,在_delta_log目录中json文件
- Checkpoint文件,也在日志目录中,parquet格式
事务日志
Delta Lake事务日志(aka DeltaLog)是从Delta Lake表创建以来在其上执行的每次事务操作的有序记录,作为single source of truth跟踪所有对表的变更对用户始终提供正确的数据视图。事务日志是Delta Lake的关键,是最重要功能的基础,包括 ACID 事务、可扩展的元数据处理、时间旅行等。如上图所示,在_delta_log目录中的一系列的JSON对象,每次事务提交都会创建一个JSON文件,按照递增的zero-padded的数字IDs的命名规范,从000000.json开始,下一次提交为000001.json,随后为000002.json,依此类推。

当用户对表执行一个修改操作(比如,INSERT,UPDATE,或DELETE),Delta Lake把这个操作拆分成若干个应用到之前版本的action,写入日志中,如上图所示。这些action包括:
- Change Metadata,metaAction是更改表的metadata,包括schema,分区,存储格式(Parquet等),是否append-only
- Add or Remove Files,add action除了为数据对象增加的records,还包括统计数据,比如records count,每列的min/max和null数量,remove action包含一个时间戳标示remove什么时候发生的,真正物理删除数据是发生超过用户指定的阈值(retention configuration)之后,在这之前remove action作为一个墓碑(tombstone)保留在log中
- dataChange flag,标示数据是否发生变更(add/remove action时),比如流式查询会tailing事务日志,这个flag可以用来忽略不会影响结果的action(比如,改变之前的数据文件的排序)
- Protocol Evolution,protocol action增加读写Delta表的协议版本,在增加新功能的同时标示哪个版本的client会兼容
- Add Provenance Information,每个log条目也可以包含治理信息在一个commitInfo action中,比如,某个commit是哪个用户在什么时间做了什么操作
- Update Application Transaction IDs,Delta Lake为applications提供了方法在log条目中写入txn action,携带appId和version字段,记录application-specific信息(比如,输入流的offset),这些信息与其相关的add/remove action在同一条log record中,它们用来辅助实现端到端的事务应用
Log Checkpoint
为了提升性能,需要周期性的合并日志,去除冗余actions,通过checkpoint将到某个日志记录ID的所有的non-redundant actions记录到一个Parquet文件中,包括:
- 对相同数据对象的add action之后的remove action合并成一个remove action的tombstone
- 对同一对象的多次add action可以被替换成最近一个
- 相同的appId的txn action可以被替换最近一个,它包含最近的版本字段
- changeMetadata和protocol actions可以被coalesce,只保留最新的metadata
Checkpoint的最终结果就是生成一个Parquet文件,比如000003.parquet,这个checkpoint文件代表到000003.json(包含它自己)的log文件的合并。客户端默认是10次事务做一次checkpoint,并且更新其checkpoint ID到_delta_log/_last_checkpoint 对象中,客户端每次从_delta_log/_last_checkpoint中的ID开始LIST_delta_log目录,找到最新的checkpoint文件和后续的log文件,所以即使_delta_log/_last_checkpoint由于对象存储(AWS S3)最终一致性造成读到的ID落后也不会有影响。
Access Protocols
读流程
- 从
_last_checkpoint对象中获取last checkpoint ID,默认为0 - 用last checkpoint ID作为start key去做LIST操作,找出最新的checkpoint的parquet文件与其之后所有新的json log文件,用这些文件重新构造出表的状态(aka 快照),即数据对象(COW)与相关统计数据,可以通过一个Spark Job来并行执行
- 使用统计数据在查询规划时(在Driver侧)识别出与查询相关的数据对象集(比如Predicate Filters)
- 读取相关的数据对象(发生在Executor上的task执行阶段)
步骤2与4会因为最终一致性遇到某些log文件缺失(比如,000004.json与000006.json之间的000005.json暂时缺失)或者某个步骤3中规划出的数据对象找不到,只需简单的等待或者重试即可
写流程
- 使用读流程的步骤1与2找出最新的log ID,比如说r,这次事务读版本r(快照版本)的表数据,并会尝试写入log记录r+1
- 在正确的目录写入新的数据对象,使用GUIDs生成对象名,最后这些对象会被新的日志记录引用
- 原子地尝试写入日志对象r+1.json,如果失败事务将会重试,根据查询的语义,客户端可能可以复用步骤2中写入的新数据对象,然后只需要简单的更新log版本号比如r+2.json即可
- 每隔10次(默认)会做一次checkpoint,写入checkpoint parquet文件和更新
_last_checkpoint
步骤4只会影响性能,失败或者部分失败不会影响正确性,所以如果第3步成功,这次写事务将自动提交。
Reference
- https://www.youtube.com/watch?v=nWwQMlrjhy0
- https://www.youtube.com/watch?v=LJtShrQqYZY&list=RDCMUC3q8O3Bh2Le8Rj1-Q-_UUbA&index=2
- https://www.youtube.com/watch?v=de-6a6Bfw6E
- https://docs.databricks.com/lakehouse/acid.html
- https://docs.databricks.com/optimizations/isolation-level.html#isolation-levels
- https://www.starburst.io/blog/tag/iceberg/
- https://iceberg.apache.org/javadoc/0.11.0/org/apache/iceberg/IsolationLevel.html
- https://www.databricks.com/blog/2019/08/21/diving-into-delta-lake-unpacking-the-transaction-log.html
- https://www.databricks.com/blog/2019/09/24/diving-into-delta-lake-schema-enforcement-evolution.html
- https://www.databricks.com/blog/2020/09/29/diving-into-delta-lake-dml-internals-update-delete-merge.html