Spark Shuffle Non-amateur First Look
Spark Shuffle是什么
Spark Shuffle是spark的最核心部分之一,它涉及到RDD,DAGScheduler,Network,Storage,RPC等,也是spark中优化和问题最多的地方。在讲Shuffle之前要讲介绍下RDD,这里不讲老生常谈的弹性数据集之类的,引用大神Michael Armbrust的经典总结,what is rdd:
- Dependencies
- Partitions (with optional locality info)
- Compute Function: Partition => Iterator[T]
Dependencies是该RDD依赖的RDD,Partitions是该RDD要处理的数据分片,Compute是apply到该RDD的数据的方法(Spark是基于函数式编程思想),compute function本身是opaque,返回类型T也是opaque的,这里是不是有点volcano中mechanism与policy分离的味道。与之对应在RDD类中有compute方法,getPartitions方法和getDependencies方法。
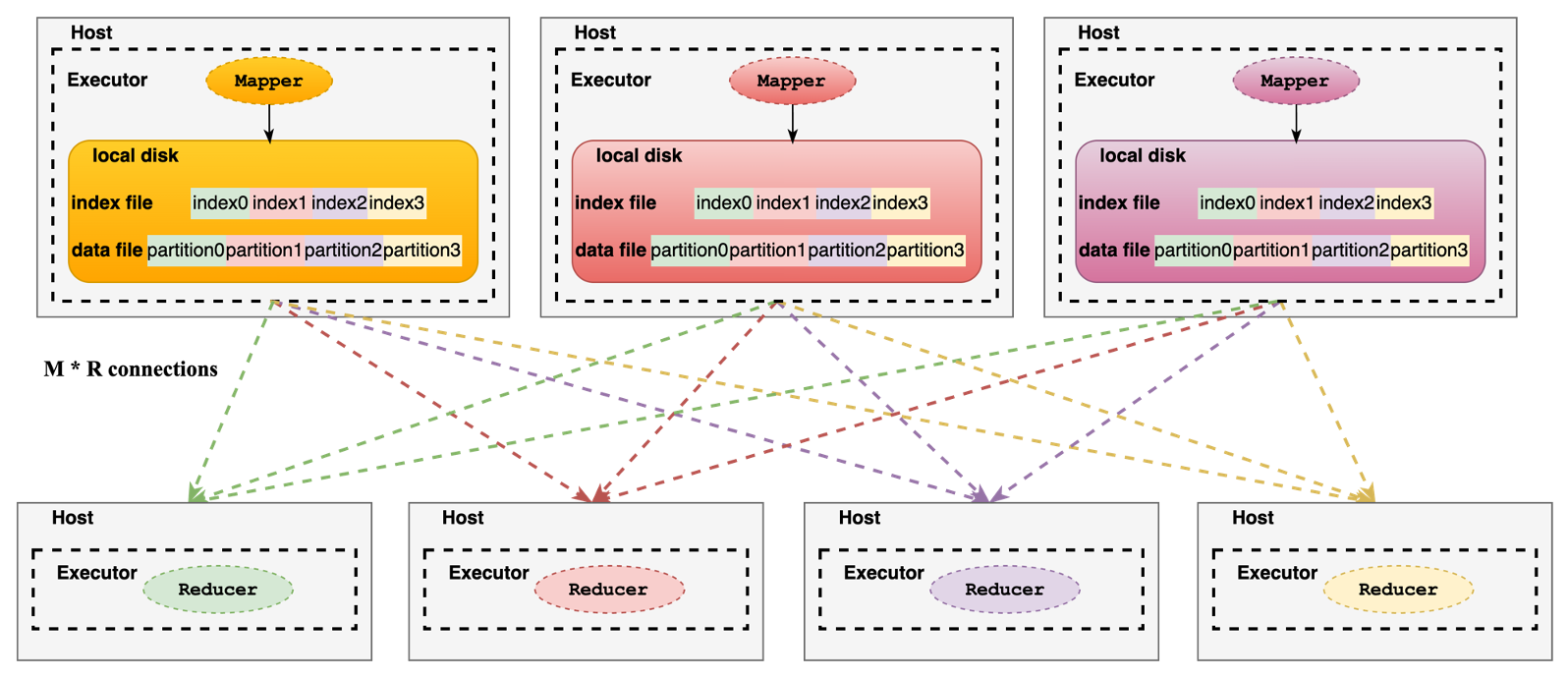
Shuffle是分布式计算框架用来衔接上下游任务的数据重分布过程,spark shuffle存在于宽依赖的RDD之间,它是pull & file base的。上游Map Task最终会合并产出一个按照partition排序(key排序不强制)的data和index文件,由下游的Reduce Task去拉取各自需要处理的partition的数据,也就说上游产出多少个partition,下游就会起多少个task去处理,其中partition数量可以通过默认参数spark.sql.shuffle.partitions,spark.default.parallelism指定,或者自定义partitioner决定。这里会有两个问题:
- 如何划分上下游,也就是划分Stage?
- 某个Stage如何知道需要多少个map task去拉取上游stage的shuffle数据,和产出多少个partition数据给下游
如何划分
Shuffle划分stage,每个stage中一般会有一个RDD是ShuffleRDD(同一stage中可能多个窄依赖的rdd),用经典的WordCount例子来看。
1 | val rdd1 = spark.sparkContext.textFile("file:///data/macduan/test_words") |
通过rdd6.toDebugString发现有3个stage,以中间的stage为例子,它包含MapPartitionsRDD和一个ShuffledRDD,按照DAGScheduler划分stage的逻辑(后续文章详解)MapPartitionsRDD的parent rdd是ShuffledRDD,此时该Stage的实例中成员rdd实际就是MapPartitionRDD,而该rdd的firstParent就是ShuffledRDD。
抽象出来就是,比如 ... MapPartitionsRDD <- ShuffledRDD <- MapPartitionsRDD <- ShuffledRDD <- MapPartitionsRDD ... 划分stage的边界就是ShuffledRDD,最终会被划分为,
- stage1 – [… MapPartitionsRDD]
- stage2 – [ShuffledRDD <- MapPartitionsRDD]
- stage3 – [ShuffledRDD <- MapPartitionsRDD …]
三个stage,以中间那个stage2 [ShuffledRDD <- MapPartitionsRDD]为例子,它是一个ShuffleMapStage,从下面的代码的visit函数可以看出它被划分和create的边界就是stage3的ShuffledRDD。
1 | // DAGScheduler.scala |
Task, Parition数量
从下面这两个函数可以直接看出一个map stage被创建时,map task数量和产出的reduce partition数量,分别是该stage的rdd的分区数量和partitioner的分区数量。从ShuffledRDD类也可以看出其dependency就是一个ShuffleDependency,ShuffleDependency中有partitioner,而且在其实例化时会调用registerShuffle方法,partitioner是决定这个stage写的数据的分区数量,该数量也是下游stage的task数量。
1 | def createShuffleMapStage |
那么问题来了,stage2自身的task数量是怎么知道的呢(也就是上游stage的写的分区的数量),上面分析是其rdd的partition数量,那这个rdd的partition数量又是怎么来的呢?
在createShuffleMapStage中rdd是shuffleDep.rdd也就是stage2的MapPartitionsRDD,numTasks是rdd的partitions的length,也就是MapPartitionsRDD.getPartitions的length,从下面代码可以看到是其第一个parent的partition数量,往上追溯那就是stage1的ShuffledRDD的partitions数量,也就是其partitioner的分区数量,这就对应上了上游stage的写的数据的分区数量。
1 | class ShuffledRDD[K: ClassTag, V: ClassTag, C: ClassTag]( |
再探Task
1 | // Stage.scala |
Spark的每个Job除了触发这个job提交的finalRDD(例如上面的rdd6如果调用了collect()那么它就是这个finalRDD)中的task是ResultTask,其它stage中的task都是ShuffleMapTask。
ShuffleMapTask中有一个成员是partition,就是这个task需要处理的rdd的一个partition,在DAGScheduler.submitMissingTasks中有一段代码亦可看出来,上面的stage1的某个ShuffleMapTask就是处理MapPartitionsRDD的一个partition。
1 | partitions = stage.rdd.partitions |
ShuffleMapTask中最重要的方法是runTask,里面会反序列化得到RDD(task在跑在Executor上,由Driver分发的),从SparkEnv中拿到ShuffleManager获取writer等(这些在后续文章中会详细介绍),其中很关键的一行代码是writer.write(rdd.iterator(partition, context).asInstanceOf[Iterator[_ <: Product2[Any, Any]]])
在本文的例子的stage1的ShuffleMapTask中,这里既包含读Shuffle数据也包含写处理完读取的shuffle数据后写入新的shuffle数据,其中的rdd就是上面提到的MapPartitionsRDD。write的参数rdd.iterator(partition, context),这个iterator方法最终会调用MapPartitionsRDD的compute方法,
1 | // MapPartitionsRDD.scala |
这里的firstParent就是MapPartitionsRDD依赖的ShuffledRDD,而ShuffledRDD的iterator方法最终会调用它的compute方法,
1 | // ShuffledRDD.scala |
这个方法会通过ShuffleManager拿到Shuffle reader然后读取上游阶段的shuffle数据。到这里Shuffle怎么产生的,读和写发生哪里都比较清晰的介绍了。