Spark SQL: Relational Data Processing in Spark
What Is Spark SQL
Spark SQL是Apache Spark的一个新的模块,为其提供了原生的SQL支持。Spark SQL主要通过一下两方面的贡献弥合了关系与过程这两类处理模型之间的差异,
- Spark SQL提供了DataFrame API,可以在外部数据源和Spark内置的分布式集合(RDD)上进行查询
- Spark SQL提供了一个全新的可扩展的优化器,Catalyst,使其支持广泛的数据源和算法,方便增加数据源,优化规则和数据类型
DataFrame
DataFrame是结构数据的集合,可以被Spark的过程式API,或新的关系型API(允许更丰富的优化)操作,DataFrame API提供了丰富的关系/过程集成。DataFrame可以被直接从spark内置的分布式Java/Python对象集合创建,在现有的Spark程序中使用关系型处理。在大多数场景下,DataFrame比使用Spark的过程式API(传统RDD方式)更方便和高效,比如,它可以通过一条SQL语句实现多个聚合,然后DataFrame自动使用列格式存储数据,比Java/Python对象更精凑,最后,与R和Python的DataFrame不同的是Spark SQL的DataFrame的操作会经过关系型优化器,Catalyst。
Catalyst
Spark SQL为了支持更广泛的数据源和分析负载,设计了一个可扩展的查询优化器,Catalyst,提供了一个通用的transforming trees框架,用来进行分析,规划,运行时代码生成。Catalyst还支持新数据源扩展,包括半结构化数据,支持filters下推的数据源, 支持UDF,支持机器学习领域的UDT(user defined types)。
Why Spark SQL
早期的大数据系统,比如MapReduce,只提供了low-level,过程式编程接口,需要用户进行繁重的手动优化来达到高性能。许多新的系统,比如Hive,Dremel和Shark,都利用声明式查询来提供更丰富的自动优化。在许多数据管道任务中,用户既想使用声明式查询关系型系统(比如,Hive,MySQL),又想使用过程式进行复杂处理(比如,处理飞结构化数据,机器学习)。不幸的是,关系型与过程式,这两类系统直到现在还基本上保持脱节,迫使用户只能选择其中一种范式。
Spark SQL Deep Dive
Background and Goals
Spark & RDD Overview
Apache Spark是一个通用的分布式计算引擎,提供了函数式编程API让用户操作分布式弹性数据集(RDD,Resilient Distributed Datasets),比如,map,filter,reduce等。RDD使用lineage支持容错,即通过lineage重建“缺失”的分区。RDD是lazy的,通过action触发计算,虽然RDD可以提供一些非常有用的优化(比如,pipelining operations),但是是非常有限的,因为引擎不能理解RDDs中数据的结构(任意的Java/Python对象),或者用户函数的语义(任意的代码)。
Design Goals
- 支持关系型处理的程序员友好的API,在使用RDD是Spark程序和外部数据源
- 使用数据库管理系统中已有的技术提供更高的性能
- 更容易支持新的数据源,包括半结构数据,外部数据源,能更好的支持联邦查询
- 支持扩展高级的分析算法,比如机器学习,图处理
Programming Interface
Spark SQL作为一个库运行在Spark上,提供了SQL接口(通过JDBC/ODBC,Console连接)和DataFrame API(与Spark支持的编程语言集成,Scala/Java/Python)。

DataFrame API
DataFrame是一个相同schema的分布式的行集,相当于关系数据库中的一个表。用户在DataFrame上使用类似R data frames和Python Pandas的DSL进行关系型操作,它支持所有常见的关系算子,包括project(select),filter(where),join和aggregation(groupBy),这些运算符都接受受限的DSL的表达式对象,让 Spark捕获表达式的结构。下面是一段是从hive表定义一个部门,雇员的DataFrame,并且计算每个部门女性雇员数量的代码,
1 | val ctx = new HiveContext() |
上面计算部门女性雇员数量的代码片段中所有的算子会建立一个抽象语法树(AST),传递给Catalyst框架优化。除了关系型DSL,DataFrame还支持在系统Catalog中注册为一个临时表和使用SQL查询,
1 | users.where(users("age") < 21).registerTempTable("young") |
Data Model
Spark SQL使用基于Hive的嵌套数据模型,它支持所有主要的SQL数据类型,包括boolean,integer,double,decimal,string,date,timestamp,以及复杂(non-aotmic)数据类型:struct,arrays,maps和unions。复杂数据类型也可以被嵌套到一起创建一个更强大的类型。Spark SQL对复杂类型查询提供了非常好的支持,并且UDT(user-defined type)。使用这种类型系统,我们可以准确的从各种源和格式中建模数据,包括Hive,关系数据库,JSON和Java/Scala/Python中的原生对象。
为了与过程式Spark代码交互,Spark SQL允许用户直接对编程语言原生对象的RDD构建DataFrame,使用反射自动推导这些对象的schema。对于Scala和Java,这些类型信息是从其类型系统中提取(从JavaBeans和Scala case class中),对于Python(动态类型系统),则是通过采样数据集来推导schema。
User-Defined Functions
User Defined-Functions(UDFs)是数据库系统的一个重要扩展,比如MySQL依赖UDFs支持JSON数据,Postgres等使用MADLib的UDFs实现机器学习算法,但是这些都需要在单独环境中定义UDFs,与primary的查询接口不同。然而,Spark SQL的DataFrame API对UDF的支持不需要复杂打包和注册过程,可以通过传递Scala/Java/Python函数来支持内联UDFs定义,这些函数还可以在内部使用Spark API。
1 | val model: LogisticRegression = ... |
Catalyst
Catalyst优化器是Spark SQL的核心,它是基于Scala函数式编程特性(例如,模式匹配和偏函数)来构建的可扩展的查询优化器,有两个关键的设计:
- 便于在Spark SQL中增加新的优化功能
- 允许外部开发人员扩展优化器,添加数据源特定规则、支持新数据类型等
Catalyst的核心包括一个通用的表达trees的库和操作它们的rules,在此框架之上它构建了关系查询特有的处理库(例如,表达式、逻辑查询计划),以及处理查询执行不同阶段的几组规则:分析、逻辑优化、物理规划和编译代码生成。Catalyst支持基于规则和基于成本的优化(RBO & CBO),还提供了几个公共扩展点,包括外部数据源和用户定义的类型。
Trees
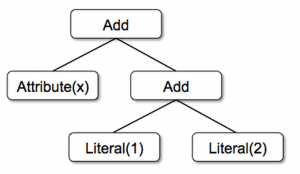
Catalyst中的主要数据类型是由节点对象组成的树。每个节点都有一个节点类型和零个或多个子节点。新节点类型在Scala中定义为TreeNode 类的子类。 这些对象是不可变的,可以使用函数转换来操作,作为一个简单的例子,假设我们有以下三个用于非常简单的表达式语言的节点类:
- **
Literal(value: Int)**,一个常量 - **
Attribute(name: String)**,一个输入行的属性 - **
Add(left: TreeNode, right: TreeNode)**,两个表达式的和
Rules
Rules是操作Trees的函数,一个rule是将一个tree转换成另一个tree的函数,最常见的方法就是使用一组pattern matching函数查找和替换子树为新的结构。在Catalyst中,trees提供一个transform方法,在树的所有节点上递归应用pattern matching函数,比如下面的规则应用到x+(1+2)的表达式树上,会产出一个新的x+3的树。
1 | tree.transform { |
Catalyst把rules分组到batches,每个batch做一类优化,一个batch会一直执行到一个fixed point(比如,到达最大循环次数),rule的conditions和bodies可以是任意的scala代码,这使得Catalyst更容易实现各种rules。
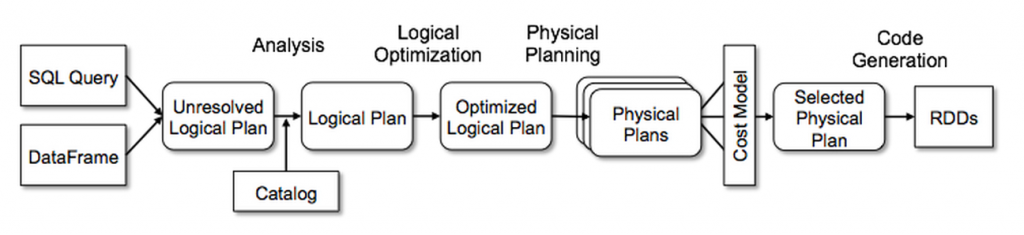
从上图可以看到,Catalyst框架包含4个阶段(与关系数据库类似),
- 分析一个逻辑计划,解析起引用
- 逻辑优化
- 物理规划
- 代码生成,编译部分代码为Java bytecode
Using Catalyst in Spark SQL
Analysis
Spark SQL开始于一个要被计算的relation,它来自SQL解析器返回的抽象语法树 (AST),或者从使用API构造的DataFrame对象。 在这两种情况下,relation可能包含未解析的属性引用或关系,例如,在SQL查询SELECT col FROM sales中,我们无法知道col的类型,甚至不知道它是否是一个有效的列名,直到我们查找sales表。
如果我们不知道它的类型或没有将它与输入表(或别名)匹配,则称为未解析的属性(Attributes)。 Spark SQL使用Catalyst rules和一个Catalog对象来跟踪所有数据源中的表来解析这些属性。 它首先构建一个具有未绑定属性和数据类型的“未解决的逻辑计划”树,然后应用执行以下操作的规则:
- 从
catalog中查找relations - 将命名属性(例如,
col)映射到给定运算符的子项提供的输入 - 确定哪些属性引用相同的值,赋予一个唯一的ID(稍后允许优化表达式如,
col = col) - 通过表达式传播和强制类型:例如,在解析
col之前我们无法知道1 + col的类型,并可能将其子表达式转换为兼容类型
Logical Optimization
逻辑优化阶段将基于标准规则的优化应用于逻辑计划。这些包括常量折叠、谓词下推、投影裁剪、空值传播、布尔表达式简化和其他规则。 总而言之,为各种情况添加规则非常简单。
Physical Planning
在物理规划阶段,Spark SQL将一个逻辑计划生成一个或多个使用与Spark执行引擎相匹配的物理算子组成的物理计划(比如join算子选择)。物理规划还可以执行基于规则的物理优化,例如将投影或过滤器流水线化到一个 Spark的map操作中。 此外,它可以将操作从逻辑计划推送到支持谓词或投影下推的数据源。
Extension Point
Catalyst还定义了两个更窄的公共扩展点:数据来源和用户定义的类型。 这些仍然依赖于设施核心引擎与优化器的其余部分进行交互。
Data Sources
开发人员可以使用多个API为Spark SQL定义一个新的数据源,这些API暴露了不同程度的优化可能性。 所有数据源都必须实现一个createRelation函数,该函数采用一组键值参数并返回该关系的BaseRelation对象(如果可以成功加载的话)。 每个BaseRelation包含一个schema和一个可选的大小估值(以字节为单位)。例如,表示 MySQL的数据源可能将表名作为参数,并要求MySQL提供表大小的估值。 为了让Spark SQL读取数据,BaseRelation可以实现多个接口之一,让它们暴露不同程度的复杂性。最简单的 TableScan需要关系返回表中所有数据的Row对象的RDD。更高级的PrunedScan需要一个列名数组来读取,并且应该返回仅包含这些列的行。第三个接口PrunedFilteredScan接受所需的列名和Filter对象数组,它们是Catalyst表达式语法的子集,允许谓词下推。过滤器是建议性的,即数据源应尝试仅返回通过每个过滤器的行,但在无法评估的过滤器的情况下,允许返回false positive。 最后,为CatalystScan接口提供了完整的Catalyst表达式树序列,以用于谓词下推,尽管它们再次是建议性的。Spark SQL已经使用这些接口实现了以下数据源:
- CSV文件,简单的扫描整个文件,但是允许用户指定一个schema
- Avro,一种自描述的嵌套数据的二进制格式
- Parquet,一种列式存储格式,支持列裁剪与过滤
- JDBC,可以并行扫描RDBMS表的一部分,支持过滤下推
User-Defined Types
数据类型遍及执行引擎的各个方面,例如,在Spark SQL中机器学习应用程序可能需要向量类型,图形算法可能需要表示图形的类型。然而,Spark SQL中增加新类型具有挑战性,例如,在Spark SQL中,内置数据类型以列式压缩格式存储在内存缓存中,在数据源API中,需要将所有可能的数据类型暴露给数据源作者。Catalyst通过关联user-defined types到Catalyst的内置类型组成的structures来解决这些问题。要将Scala类型注册为UDT,用户需要提供从其类的对象到内置类型的Catalyst Row的映射,以及反向映射。这样可以在使用 Spark SQL查询的对象中使用Scala类型,并且它会在后台转换为内置类型。同样,他们可以注册直接在其类型上运行的UDF。
1 | class PointUDT extends UserDefinedType[Point] { |
注册此类型后,Points将在要求Spark SQL转换为DataFrames的原生对象中被识别,并将传递给在Points上定义的UDF。此外,Spark SQL在缓存数据时会将Points以列格式存储(将x和y压缩为单独的列),Points将可写到Spark SQL的所有数据源,这些数据源会将它们视为成对的DOUBLE。
Reference
- https://www.databricks.com/glossary/what-is-spark-sql
- https://www.databricks.com/research/spark-sql-relational-data-processing-in-spark
- https://www.databricks.com/session/catalyst-a-query-optimization-framework-for-spark-and-shark
- https://www.databricks.com/blog/2015/04/13/deep-dive-into-spark-sqls-catalyst-optimizer.html
- https://www.databricks.com/blog/2016/07/14/a-tale-of-three-apache-spark-apis-rdds-dataframes-and-datasets.html
- https://cwiki.apache.org/confluence/display/hive/languagemanual+ddl
- https://dl.acm.org/doi/10.14778/1687553.1687576