SIMD Basic Using AVX and AVX2
What Is SIMD
SIMD代表单指令多数据(Single Instruction, Multiple Data)。它是一种计算机指令集架构,旨在同时处理多个数据元素。SIMD指令允许在单个指令中对多个数据元素执行相同的操作,从而实现并行处理和向量化计算。
在SIMD架构中,数据被组织为向量(也称为寄存器),其中每个向量元素都可以是整数、浮点数或其他数据类型。SIMD指令可以同时对向量中的多个元素执行相同的操作,例如加法、乘法、逻辑运算等。这种并行处理方式可以显著加速计算过程,尤其是在处理大规模数据集时。
现代处理器和图形处理器(GPU)通常支持SIMD指令集,如Intel的SSE(Streaming SIMD Extensions)和AVX(Advanced Vector Extensions),以及ARM的NEON(Advanced SIMD)。这些指令集提供了丰富的SIMD操作,使开发者能够利用硬件并行性来优化程序性能。
Fundamentals of AVX Programming
SIMD Data Type
| Data Type | Description |
|---|---|
| __m128 | vector containing 4 floats |
| __m128d | vector containing 2 doubles |
| __m128i | vector containing integers |
| __m256 | vector containing 8 floats |
| __m256d | vector containing 4 doubles |
| __m256i | vector containing integers, int8/32/64, uint8/32/64 |
Function Naming Conventions
_mm<bit_width>_<name>_<data_type>
- bit_width,函数返回的vector的宽度. 空代表128-bit vectors, 256代表256-bit vectors.
- name,intrinsic操作如
add,set,shuffle等 - data_type,函数主要参数的数据类型,详细如下
ps- float vectors (ps stands for packed single-precision)pd- double vectors (pd stands for packed double-precision)epi8/epi16/epi32/epi64- signed integer vectorsepu8/epu16/epu32/epu64- unsigned integer vectorssi128/si256- unspecified 128-bit vector or 256-bit vectorm128/m128i/m128d/m256/m256i/m256d- identifies input vector types when they’re different than the type of the returned vector
一个简单例子
set_ps.cpp
1 |
|
运行结果
1 | g++ -mavx2 set_ps.cpp |
Initialization Intrinsics
在对AVX向量进行操作之前,需要填充向量数据,有两种方法可以实现这一点:使用标量值初始化向量和使用从内存加载的数据初始化向量。
Initialization with Scalar Values
AVX提供了将一个或多个值组合成256位向量的内嵌函数,还有类似的内嵌函数可以初始化128位向量,但这些函数是由SSE提供的,而不是AVX。这些函数的名称唯一的区别是将_mm256_替换为_mm_。
| Function | Description |
|---|---|
| _mm256_setzero_ps/pd | Returns a floating-point vector filled with zeros |
| _mm256_setzero_si256 | Returns an integer vector whose bytes are set to zero |
| _mm256_set1_ps/pd | Fill a vector with a floating-point value |
| _mm256_set1_epi8/epi16/epi32/epi64 | Fill a vector with an integer |
| _mm256_set_ps/pd | Initialize a vector with eight floats (ps) or four doubles (pd) |
| _mm256_set_epi8/epi16/epi32/epi64 | Initialize a vector with integers |
| _mm256_set_m128/m128d/m128i | Initialize a 256-bit vector with two 128-bit vectors |
| _mm256_setr_ps/pd | Initialize a vector with eight floats (ps) or four doubles (pd) in reverse order |
| _mm256_setr_epi8/epi16/epi32/epi64 | Initialize a vector with i |
Example
1 |
|
1 | gcc -O3 -mavx2 test.cpp |
这里用_mm256_setr_epi32而不是_mm256_set_epi32主要是为了更自然的展示set的效果(从0到7),负数最高位的bit是1,所以_mm256_maskload_epi32选择性到将前5个数据load到result中了。
Loading Data from Memory
AVX/AVX2的常见用法是将数据从内存加载到向量中,对向量进行处理,然后将结果存回内存。
| Data Type | Description |
|---|---|
| _mm256_load_ps/pd | Loads a floating-point vector from an aligned memory address |
| _mm256_load_si256 | Loads an integer vector from an aligned memory address |
| _mm256_loadu_ps/pd | Loads a floating-point vector from an unaligned memory address |
| _mm256_loadu_si256 | Loads an integer vector from an unaligned memory address |
| _mm_maskload_ps/pd / _mm256_maskload_ps/pd | Load portions of a 128-bit/256-bit floating-point vector according to a mask |
| _mm_maskload_epi32/64 / _mm256_maskload_epi32/64 | Load portions of a 128-bit/256-bit integer vector according to a mask |
Arithmetic Intrinsics
Addition and Subtraction
| Data Type | Description |
|---|---|
| _mm256_add_ps/pd | Add two floating-point vectors |
| _mm256_sub_ps/pd | Subtract two floating-point vectors |
| _mm256_add_epi8/16/32/64 | Add two integer vectors |
| _mm236_sub_epi8/16/32/64 | Subtract two integer vectors |
| _mm256_adds_epi8/16/_epu8/16 Add two integer vectors with saturation | |
| _mm256_subs_epi8/16/epu8/16 Subtract two integer vectors with saturation | |
| _mm256_hadd_ps/pd | Add two floating-point vectors horizontally |
| _mm256_hsub_ps/pd | Subtract two floating-point vectors horizontally |
| _mm256_hadd_epi16/32 | Add two integer vectors horizontally |
| _mm256_hsub_epi16/32 | Subtract two integer vectors horizontally |
| _mm256_hadds_epi16 | Add two vectors containing shorts horizontally with saturation |
| _mm256_hsubs_epi16 | Subtract two vectors containing shorts horizontally with saturation |
| _mm256_addsub_ps/pd | Add and subtract two floating-point vectors |
Multiplication and Division
| Data Type | Description |
|---|---|
| _mm256_mul_ps/pd | Multiply two floating-point vectors |
| _mm256_mul_epi32/epu32 | Multiply the lowest four elements of vectors containing 32-bit integers |
| _mm256_mullo_epi16/32 | Multiply integers and store low halves |
| _mm256_mulhi_epi16/epu16 | Multiply integers and store high halves |
| _mm256_mulhrs_epi16 | Multiply 16-bit elements to form 32-bit elements |
| _mm256_div_ps/pd | Divide two floating-point vectors |
Fused Multiply and Add (FMA)
两个N位数相乘的结果可以占据2N位。因此,当您将两个浮点数a和b相乘时,实际上得到的结果是round(a * b),其中round(x)返回最接近x的浮点数值。随着进一步的操作,精度损失会增加。AVX2提供了将乘法和加法融合在一起的指令。也就是说,它们返回的结果是round(a * b + c),而不是round(round(a * b) + c)。因此,这些指令比分别执行乘法和加法提供了更高的速度和精度。
| Data Type | Description |
|---|---|
| _mm_fmadd_ps/pd / _mm256_fmadd_ps/pd | Multiply two vectors and add the product to a third (res = a * b + c) |
| _mm_fmsub_ps/pd / _mm256_fmsub_ps/pd | Multiply two vectors and subtract a vector from the product (res = a * b - c) |
| _mm_fmadd_ss/sd | Multiply and add the lowest element in the vectors (res[0] = a[0] * b[0] + c[0]) |
| _mm_fmsub_ss/sd | Multiply and subtract the lowest element in the vectors (res[0] = a[0] * b[0] - c[0]) |
| _mm_fnmadd_ps/pd / _mm256_fnmadd_ps/pd | Multiply two vectors and add the negated product to a third (res = -(a * b) + c) |
| _mm_fnmsub_ps/pd / _mm256_fnmsub_ps/pd | Multiply two vectors and add the negated product to a third (res = -(a * b) - c) |
| _mm_fnmadd_ss/sd | Multiply the two lowest elements and add the negated product to the lowest element of the third vector (res[0] = -(a[0] * b[0]) + c[0]) |
| _mm_fnmsub_ss/sd | Multiply the lowest elements and subtract the lowest element of the third vector from the negated product (res[0] = -(a[0] * b[0]) - c[0]) |
| _mm_fmaddsub_ps/pd / _mm256_fmaddsub_ps/pd | Multiply two vectors and alternately add and subtract from the product (res = a * b - c) |
| _mm_fmsubadd_ps/pd / _mmf256_fmsubadd_ps/pd | Multiply two vectors and alternately subtract and add from the product (res = a * b - c) |
Example
1 |
|
1 | g++ -mavx2 -mfma test.cpp |
Permuting and Shuffling
许多应用程序需要重新排列向量元素,以确保操作正确执行。AVX/AVX2提供了许多内嵌函数来实现这个目的,其中两个主要类别是_permute_函数和_shuffle_函数。
Permuting
| Data Type | Description |
|---|---|
| _mm_permute_ps/pd / _mm256_permute_ps/pd | Select elements from the input vector based on an 8-bitcontrol value |
| _mm256_permute4x64_pd / _mm256_permute4x64_epi64 | Select 64-bit elements from the input vector based on an 8-bit control value |
| _mm256_permute2f128_ps/pd | Select 128-bit chunks from two input vectors based on an 8-bit control value |
| _mm256_permute2f128_si256 | Select 128-bit chunks from two input vectors based on an 8-bit control value |
| _mm_permutevar_ps/pd _mm256_permutevar_ps/pd |
Select elements from the input vector based on bits in an integer vector |
| _mm256_permutevar8x32_ps _mm256_permutevar8x32_epi32 |
Select 32-bit elements (floats and ints) using indices in an integer vector |
_permute_内嵌函数接受两个参数:一个输入向量和一个8位控制值。控制值的位确定了要插入输出的输入向量元素。对于_mm256_permute_ps,每对控制位通过选择输入向量中的上半部分或下半部分元素之一,确定一个上半部分和下半部分的输出元素,如下图所示:
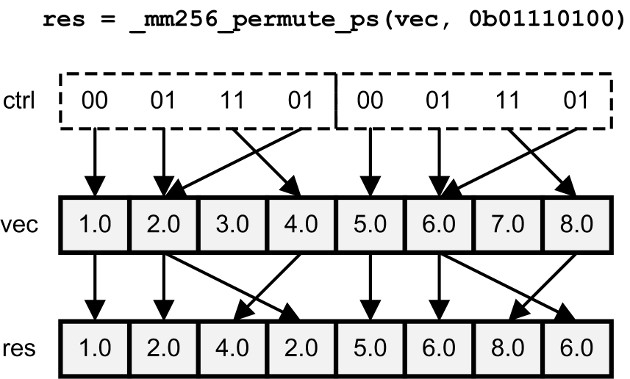
如图所示,输入向量的值可能在输出中重复多次。其他输入值可能根本不被选中。在_mm256_permute_pd中,控制值的低四位在相邻的双精度数对之间进行选择。_mm256_permute4x4_pd类似,但使用所有的控制位来选择放置在输出中的64位元素。在_permute2f128_内嵌函数中,控制值选择两个输入向量的128位块,而不是从一个输入向量中选择元素。_permutevar_内嵌函数执行与_permute_内嵌函数相同的操作。但是,它们不使用8位控制值来选择元素,而是依赖于与输入向量大小相同的整数向量。例如,_mm256_permute_ps的输入向量是_mm256,因此整数向量是_mm256i。整数向量的高位以与_permute_内嵌函数的8位控制值的位相同的方式进行选择。
Shuffling
与_permute_内嵌函数类似,_shuffle_内嵌函数从一个或两个输入向量中选择元素,并将它们放置在输出向量中。
| Data Type | Description |
|---|---|
| _mm256_shuffle_ps/pd | Select floating-point elements according to an 8-bit value |
| _mm256_shuffle_epi8 / _mm256_shuffle_epi32 | Select integer elements according to an 8-bit value |
| _mm256_shufflelo_epi16 / _mm256_shufflehi_epi16 | Select 128-bit chunks from two input vectors based on an 8-bit control value |
所有_shuffle_内嵌函数都操作256位向量。在每种情况下,最后一个参数是一个8位值,确定应该将哪些输入元素放置在输出向量中。对于_mm256_shuffle_ps,只使用控制值的高四位。如果输入向量包含整数或浮点数,所有控制位都会被使用。对于_mm256_shuffle_ps,前两对位选择第一个向量的元素,后两对位选择第二个向量的元素。
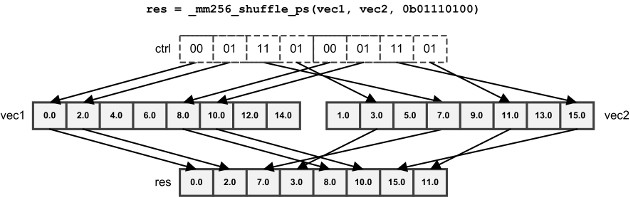
为了对16位值进行洗牌,AVX2提供了_mm256_shufflelo_epi16和_mm256_shufflehi_epi16。与_mm256_shuffle_ps类似,控制值被分为4对bits,从8个元素中进行选择。但对于_mm256_shufflelo_epi16,这8个元素来自8个低16位值。对于_mm256_shufflehi_epi16,这8个元素来自8个高16位值。
Example
1 |
|
1 | g++ -mavx2 -mfma test.cpp |