Photon: A Fast Query Engine for Lakehouse Systems
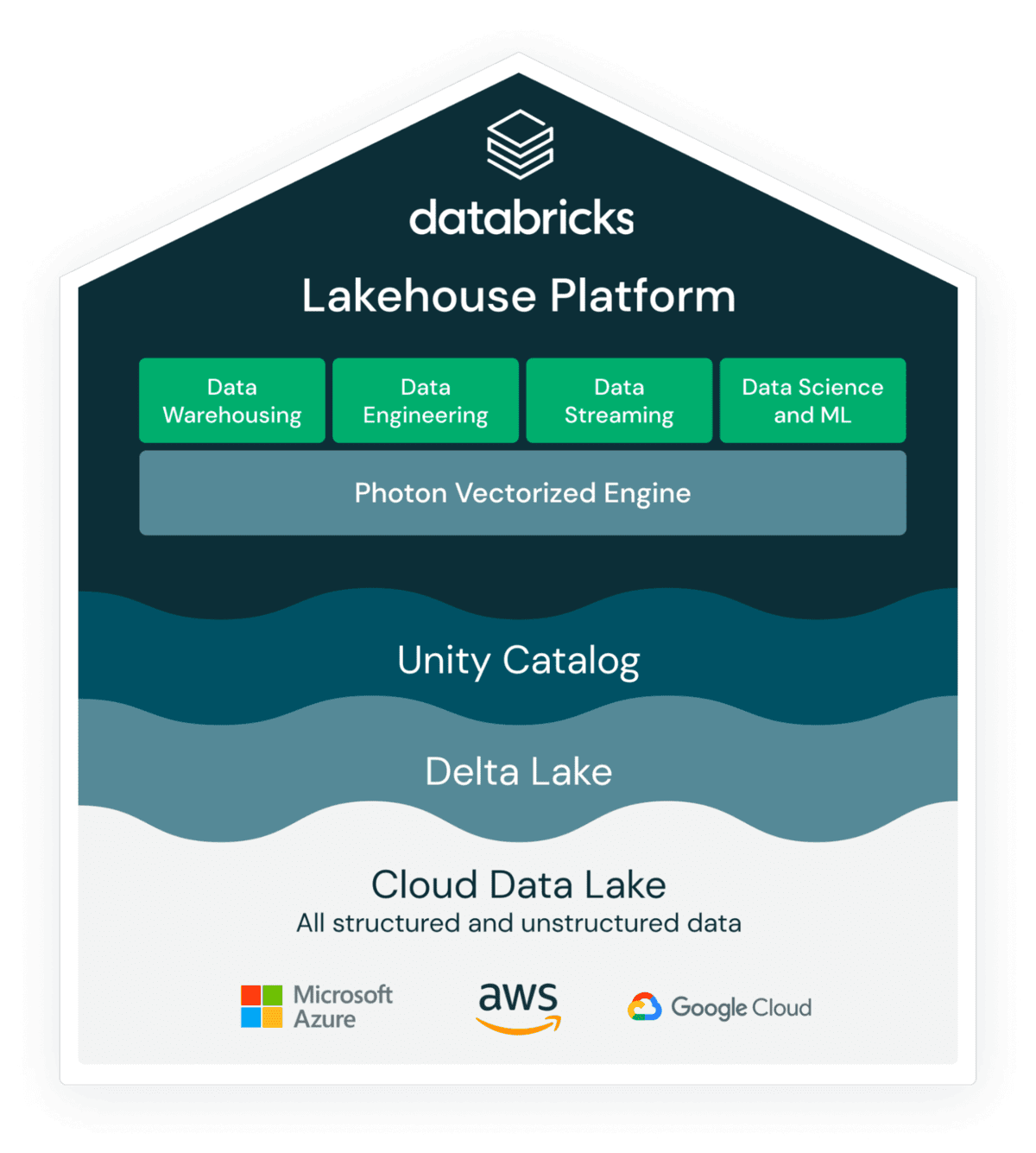
What is Photon
Photon是Databricks用C++ from scratch开发的,100%与Apache Spark兼容的(Photon是闭源的),在Databricks Lakehouse平台上新一代的向量化查询引擎,用来取代之前的Spark SQL引擎(JVM & codegen based)。Photon可直接在数据湖上以低成本提供极速的查询性能,包括数据摄取、ETL、流、数据科学和交互式查询。Photon使用C++开发,兼容Spark SQL/Dataframe API,适配了Spark memory manager,用户不需要代码更改就可使用Photon,享受其带来的性能提升。
 |
 |
Why Photon
当今的企业们将大量的数据存储在data lake中,比如Amazon S3,Azure Storage等。数据湖往往以开放数据格式的形式(Parquet,ORC)存储大量的未整理的raw data,可以被Spark,Presto这样的引擎访问,运行SQL,ML的workloads。传统的two-tier架构(data lake & data warehouse)将整理好的一部分数据从湖中移到仓中,获得数仓的高性能,治理和并发支持,这种架构复杂和昂贵,只有一部分数据可以被数仓使用,这部分数据还存在同步和时效性问题。
Databricks提出了Lakehouse架构,这种single-tier架构简化了数据治理,让用户可以使用统一的方式管理和查询所有数据,并且只需要管理更少的ETL和查询引擎。Lakehouse采用Delta Lake(也可以用Apache Iceberg)在数据湖上实现了许多数仓有的管理功能(比如,ACID Transactions,Time Travel),并且为优化存储访问提供了有用的工具,例如data clustering和data skipping indices等。然而,要最大限度提升Lakehouse的工作负载的性能,不仅要优化存储层,还需要优化查询处理,所以Databricks开发了Photon。
Photon的挑战
1. Supporting raw, uncurated data
大量的数据是未整理的,小文件,超多列,没有有用的clustering或统计,与此同时,许多用户往往希望能查询这样的数据。还有,在raw data中,string是非常方便和常见数据类型,用户习惯用string表示数字,日期,未知或缺失数据(unknown,null)的placeholder,schema信息包括nullability,字符串编码(比如,ASCII vs. UTF-8)往往是缺失的。一个极致的执行引擎必须既要在随意未整理的数据集上有好的性能,又要在整理和优化好的数据集上有超好的性能,支持的应用场景包括数据科学,ETL,ad hoc SQL,和BI。
为了应对这个挑战,Photon与Spark SQL的选择不同,使用了向量化模型而非code generation。向量化执行支持runtime adaptivity,通过对micro-batch数据的统计,选择优化执行路径,比如NotNull处理,ASCII string处理。Photon选择用native语言(C++)开发,而不是当前Databricks Runtime使用的JVM,不仅可以突破JVM自身的性能上限,JIT限制(比如,方法大小),还可以精细化控制内存管理,SIMD指令,能更好的处理大数据记录,查询计划。
2. Supporting existing Spark APIs
已经大量的用户在Databricks平台上使用Spark SQL/Dataframe,Photon必须兼容之前的语义(商业上成功的必然选择)。为了应对这个挑战,Photon紧密的集成到Databricks Runtime(DBR,Apache Spark的商业版)中。Photon作为一组新的物理算子适配到DBR中,成为可以被用于DBR优化器的查询计划的一部分,并与Spark的内存管理,指标,监控(Spark UI可以显示Photon查询)和I/O系统集成,这样既能对用户无感知,用户不用修改其workload的实现,还能让用户享受到Photon带来的好处。查询可以部分运行在Photon,对其不支持的操作可以fall back到Spark SQL的实现(JVM & Codegen),这种partially roll out的方式让Photon的推进变得顺利。
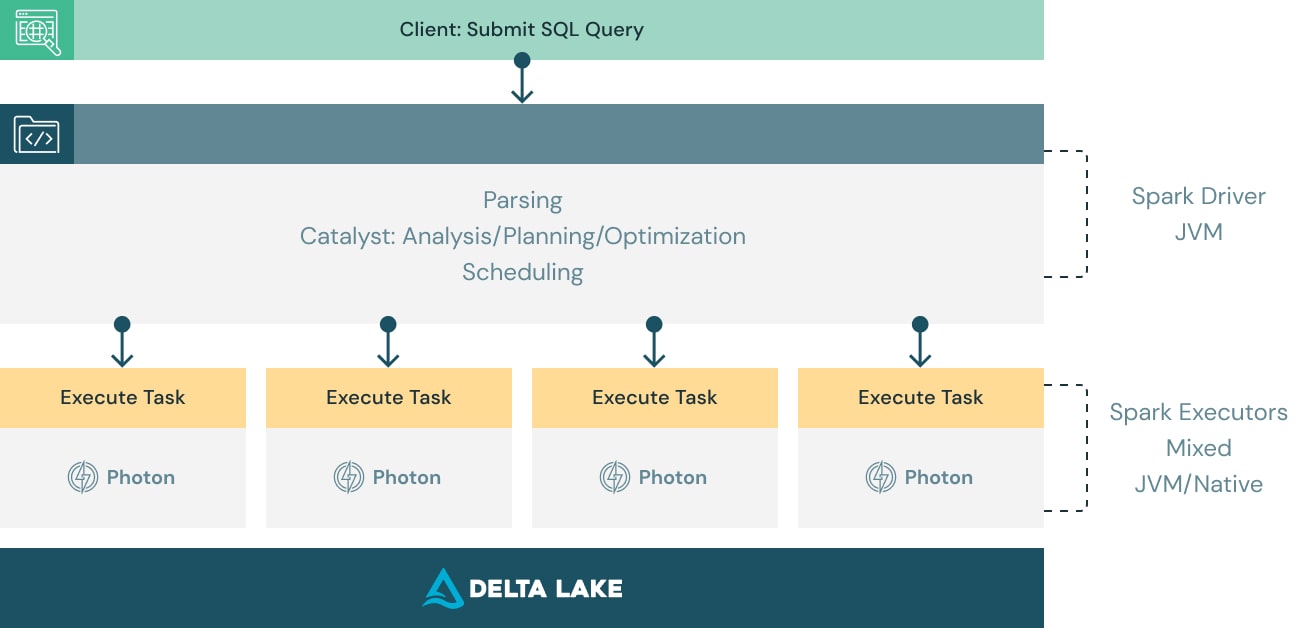
Photon Architecture
Databricks Runtime & Photon
DBR是Apache Spark的商业版,除了一些差异化的性能和稳定性优化和Spark没有区别。提交到DBR的应用被称为jobs(一般是action操作触发),每个job被分成stages。一个stage代表job的一部分,开始于读取文件或者数据交换(Scan or Exchange),结束于数据交换或者结果产出。Stages本身被分成单独的tasks,在不同的分区数据上执行相同的逻辑。Stage之间的边界是阻塞的,下一个stage的起点是上游stage的终点。DBR通过stage-by-stage的方式可以通过重执行stage或者在stage边界重新优化查询的方式实现容错与自适应执行。
DBR使用一个driver节点做调度,查询计划优化和其它中心化的任务,同时还管理多个executor节点,每个executor进程有一个调度器和线程池,以share-nothing的执行模型并行的执行driver分配的task,scan,处理和产出结果。
查询计划是一棵SQL算子树(例如,Filter、Project、Shuffle),映射到一系列的stages。在查询计划生成之后(优化后的物理计划),driver启动tasks来执行查询的每个stage。 每个任务运行都使用内存中执行引擎来处理数据。Photon就是这种执行引擎的一个例子,它取代了之前Apache Spark SQL的引擎(JVM & Codegen),如下图所示,Photon就位于DBR最底层的task中。

End-to-end SQL Query Execution
1 | SELECT |
上面的sql提交到一个driver节点之后,经过解析,逻辑优化(比如,operator re-ordering),物理优化(比如,join strategies选择),还包括partition pruning,data clustering(Z-Order)避免扫描不必要的文件等优化,一旦driver选择了哪些文件去scan并生成了最终的物理计划,就会通过Spark RDD API把查询计划转成可执行的代码,序列化后发送到每个executor节点,executor在分区数据上执行这些task的逻辑(apply function to data,函数式编程思想)。
Photon Design Decisions
How Photon Works
Photon被编译成共享库,作为executor的JVM进程的某个单线程task的一部分,被其通过JNI的方式调用。与DBR一样,Photon把一个SQL查询组成一颗算子树,每个算子使用HashNext()/GetNext()API从它的儿子节点拉取batch数据,这个API还可以通过JNI的方式从Java实现的算子中拉取数据。Photon使用向量化而非codegen的方式实现算子,所以Photon算子与Java算子的内存数据布局也不一样(一个是面向列的,一个面向行的)。
JVM vs Native Execution
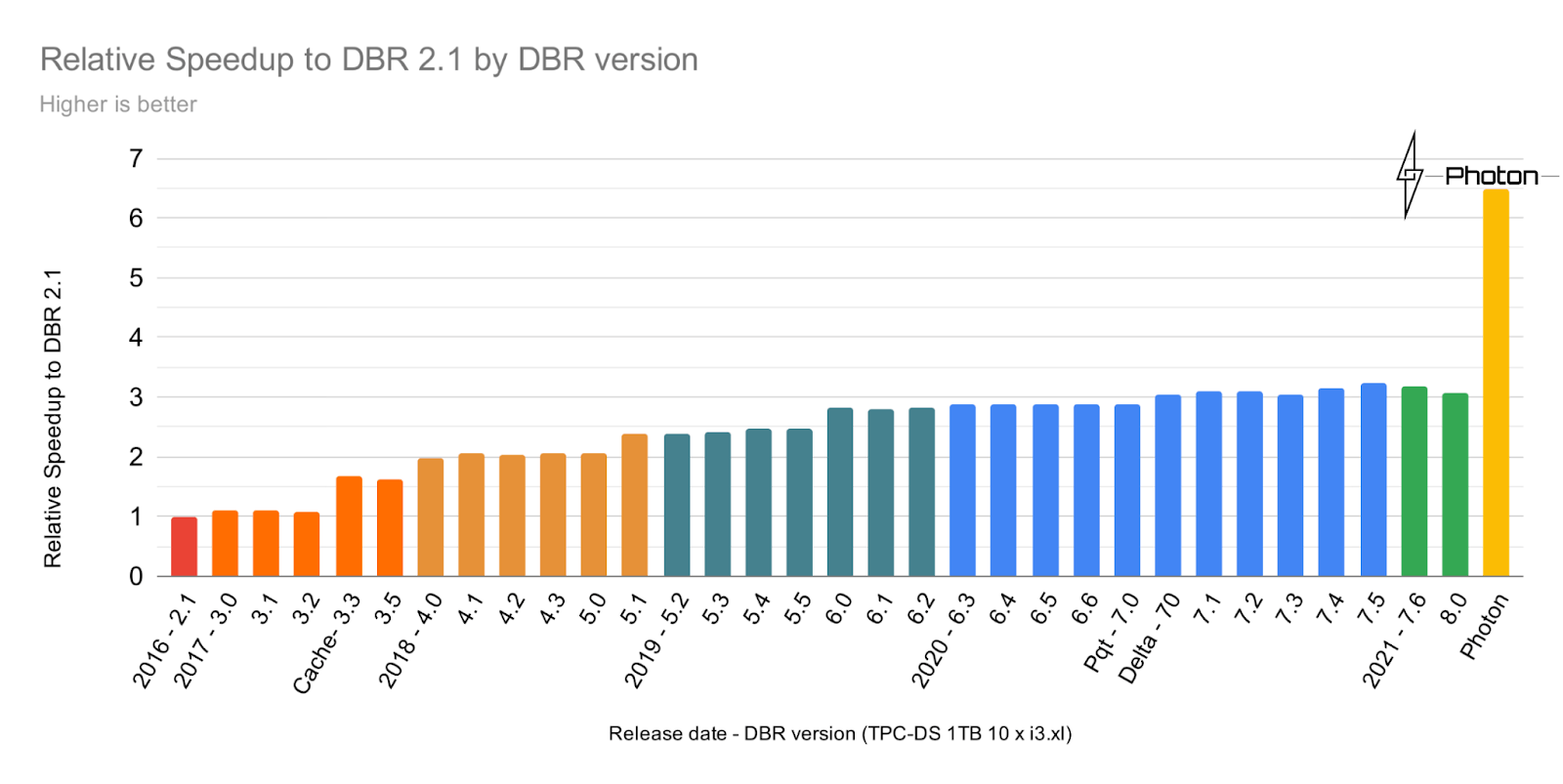
Databricks发现其workloads正在变成CPU-bound,在现有的JVM-based引擎上提升性能变得越来越困难。Local NVMe SSD caching,AQE减少了IO latency,data clustering等技术进一步减少了需要scan的文件数量,最后lakehouse上的workloads需要处理大量的非规范化的,大字符串和非结构化的嵌套数据进一步突出了内存性能。使用JIT compiler生成优化的代码(比如,使用SIMD的循环代码)需要对JVM细节理解深刻,而且缺乏对底层优化的控制,比如memory-pipelining和定制的SIMD kernels。当codegen生成的方法大小超过限制时会fall back到Volcano-styple的代码路径,而大宽表(超过100列,在lakehouse中比较常见)会超过这个限制造成性能下降。所以Databricks选择实现一个native查询引擎运行时。
Interpreted Vectorization vs. Code-Gen
向量化引擎使用动态调度机制(比如,虚函数,模板)来选择要针对给定输入执行的代码,通过按批处理数据来均摊开销,启用SIMD向量化和更好的利用cpu pipeline和memory hierarchy。Codegen系统通过在运行时使用编译器生成专门用于查询的代码来消除虚函数调用。但是向量化引擎有如下优势:
- Easier to develop and scale,更容易使用debuggers,stack trace等工具
- Observability is easier,算子之间的边界清晰,便于精确观察每个算子的指标,Codegen系统,比如Spark SQL的WholeStageCodegen把多个算子fuse到一起造成没法知道每个算子的指标
- Easier to adapt to changing data,lakehouse的数据往往缺乏约束与统计,向量化引擎可以通过batch-level的数据特性自适应选择优化的code-path
- Specialization is still possible,虽然codegen在复杂的表达式计算上有优势,但是向量化引擎也可以通过fuse特定的算子获得性能提升,比如col >= left and col <= right可以被fuse成一个算子,减少conjunction的开销,Project,Filter可以fuse成一个ProjectFilter算子
Row vs Colunmn-Oriented Execution
列式布局更适合SIMD,通过将运算符实现为紧密循环来实现更高效的数据流水线和预取,从而为数据交换与spill实现更高效的数据序列化。向量化引擎处理Lakehouse中的Parquet 等列式文件更加高效,在扫描数据时跳过可能昂贵的列到行的旋转步骤。
Partial Rollout
Photon不仅需要与执行框架(即任务调度、内存管理等)集成,还需要与现有的Spark SQL引擎集成。构建一个支持现有引擎所有功能的新执行引擎是不可能的,设计可以在新引擎中部分执行查询,然后优雅地回退到旧引擎执行支持的功能,这既是工程上的考虑也是商业上的考虑。
Vectorized Execution In Photon
Batched Columnar Data Layout
Photon是列存数据格式,每一列数据都是内存连续的,其基本数据单元是column vector,包含一个value buffer,null buffer(byte vector)。一组column vectors组成一个column batch(也就是一批row data),Photon按照column batch粒度处理数据。Column batch不仅有batch-level的元数据,比如字符串编码,还包含一个记录active rows(需要被表达式,算子处理的rows)的position list,Filters,Conditionals可以只需要操作position list,返回一个input的position list的子集合即可。

Vectorized Execution Kernels
Photon参考MonetDB/X100的execution kernels概念构建它的列式执行,execution kernels是对数据向量执行的高度优化循环的函数,比如表达式值,hash probe,数据交换的序列化,运行时统计。Execution kernels都是low-level实现,一般是依赖编译器的自动向量化和通过RESTRICT annotations辅助自动向量化,有时候会手写SIMD intrinsic,并通过C++模板特化处理不同的输入数据类型。
Vectorized Hash Table
Photon的hash table专门为向量化访问进行了优化,其查找分为三个步骤:
- 使用hashing kernel对一批键做哈希计算
- probe kernel加载指向哈希条目的指针(哈希表中的条目是按行储存,因此单个指针可以表示复合键)
- Column-by-column比较查找键,产出一个non-matching的position list,增加bucket index继续探测
其中,hashing与key比较受益于SIMD。由于probe步骤发出随机内存访问,因此它也受益于向量化(数据并行)。独立加载在kernel代码中彼此靠近,因此可以由硬件并行化(指令并行)。
Adaptive Execution
为了避免使用开销大的OS-level分配,Photon使用内部内存池和MRU(most-recently-used)机制做缓存分配与分配内存,这使得热内存被用于每个输入batch的重复分配,由于查询算子在执行期间是固定的,因此端到端处理单个输入批次所需的向量分配数是固定的。
可变长度数据(例如,字符串缓冲区)是单独管理的,使用在处理每个新批次之前释放的仅附加池。 该池使用的内存由全局内存跟踪器跟踪,因此如果引擎遇到无法容纳的大字符串,理论上可以调整批处理大小。
使用外部内存管理器单独跟踪超过任何单个批次(例如,用于聚合或连接)的大型持久分配。 我们在§5 中更详细地讨论了这些分配。 我们发现细粒度内存分配很有价值,因为与 Spark SQL 引擎不同,我们可以更稳健地处理 Lakehouse 设置中频繁出现的大型输入记录。
Adaptive Execution
Lakehouse场景下的一个主要挑战就是缺乏统计信息,元数据,或规范化的查询输入,所以Photon支持batch-level自适应,在运行时构建了batch数据的元数据,用来优化执行内核(execution kernel)选择。
- Photon中的每个执行内核都可以适应至少两个变量:batch中是否有NULL,是否有inactive rows。下面的代码中,在没有NULL时,允许分支消除提升性能,在都是active rows时可以避免通过position list间接查找,再次提升了性能并启用了SIMD。
1 | template <bool kHasNulls, bool kAllRowsActive> |
- 字符串全部采用 ASCII 编码(与一般的 UTF-8 相对),则可以使用优化的代码路径执行许多字符串表达式,还有密集hash table优化(Velox中有更详细介绍)
- 字符串的数字数据(例如整数),可以使用二进制格式更有效地对其进行序列化,许多用户将唯一标识符编码为36个字符的字符串,而不是(等效的)128 位整数
Integration With Databricks
Converting Spark Plans to Photon Plans
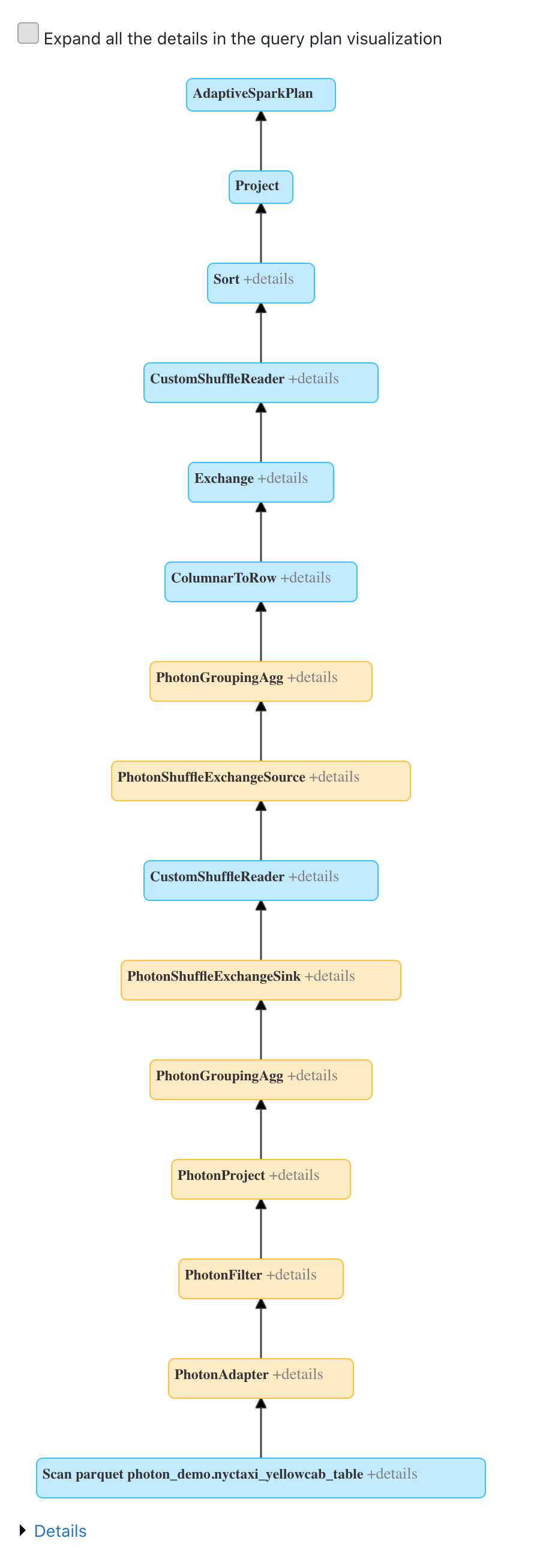
DBR将物理计划中支持photon的节点从legacy engine(Spark SQL-based engine)的节点,转换过程如下:
- 自底向上从scan节点遍历输入的计划,把legacy engine节点转成Photon节点,不转换从计划中间开始的节点,以避免从太多的列到行的转换
- 遇到不支持Photon,插入一个transition节点把列式Photon格式转成legacy engine节点行格式
- 在scan节点和第一个Photon节点之间添加了一个adapter node:这将legacy scan输入映射到Photon列式批数据,由于扫描产生的也是列式数据,因此是零拷贝

Reference
- https://www.databricks.com/wp-content/uploads/2022/07/Photon-A-Fast-Query-Engine-for-Lakehouse-Systems.pdf
- https://www.databricks.com/product/photon
- https://www.databricks.com/blog/2021/06/17/announcing-photon-public-preview-the-next-generation-query-engine-on-the-databricks-lakehouse-platform.html
- https://www.databricks.com/blog/2022/08/03/announcing-photon-engine-general-availability-on-the-databricks-lakehouse-platform.html
- https://www.databricks.com/blog/2020/06/24/introducing-delta-engine.html