How To Assemble Firebolt
Assembling a Query Engine From Spare Parts是Firebolt的一篇短文,描述了如何在不到18个月的时间内组建了一个工作的高性能云数据仓库,包括各个模块的选型的决策过程与经验教训,值得我们学习下。
What Is Firebolt
Firebolt是一个现代化的云数据仓库,旨在支持面向用户的数据密集型应用。这些工作负载具有挑战性,因为用户期望查询在几十毫秒内返回。此外,面向用户的应用程序可能有数千个同时用户和查询。它们表现出许多每秒查询数(QPS)以及高并发性。 构建数据库管理系统很难,因为它由多个复杂组件组成。这些组件包括查询引擎、存储引擎、事务管理器和系统目录。当构建云数据仓库时,这个挑战会加倍,因为它为系统增加了额外的复杂性层。这包括云平台基础设施、云存储管理、SaaS组件等等。这在下图中得到了体现,展示了Firebolt的高级架构。 即使对于一个大型团队,从头开始构建这样的系统也需要多年时间。在Firebolt,我们能够在不到18个月的时间内为真实客户推出我们的云数据仓库,运行生产工作负载。为了实现这一目标,我们从多个现有组件中组装了Firebolt。虽然有些只需要进行小的修改,但其他一些则被用作起点,并最终发生了重大变化。
Firebolt云数据仓库的高级架构。Firebolt围绕引擎的概念展开。在Firebolt中,引擎提供一组隔离的计算资源。引擎的节点运行解析器、计划器、运行时和存储引擎。通过SQL与引擎通信。周围的服务提供基本功能,如基础设施提供和元数据管理。
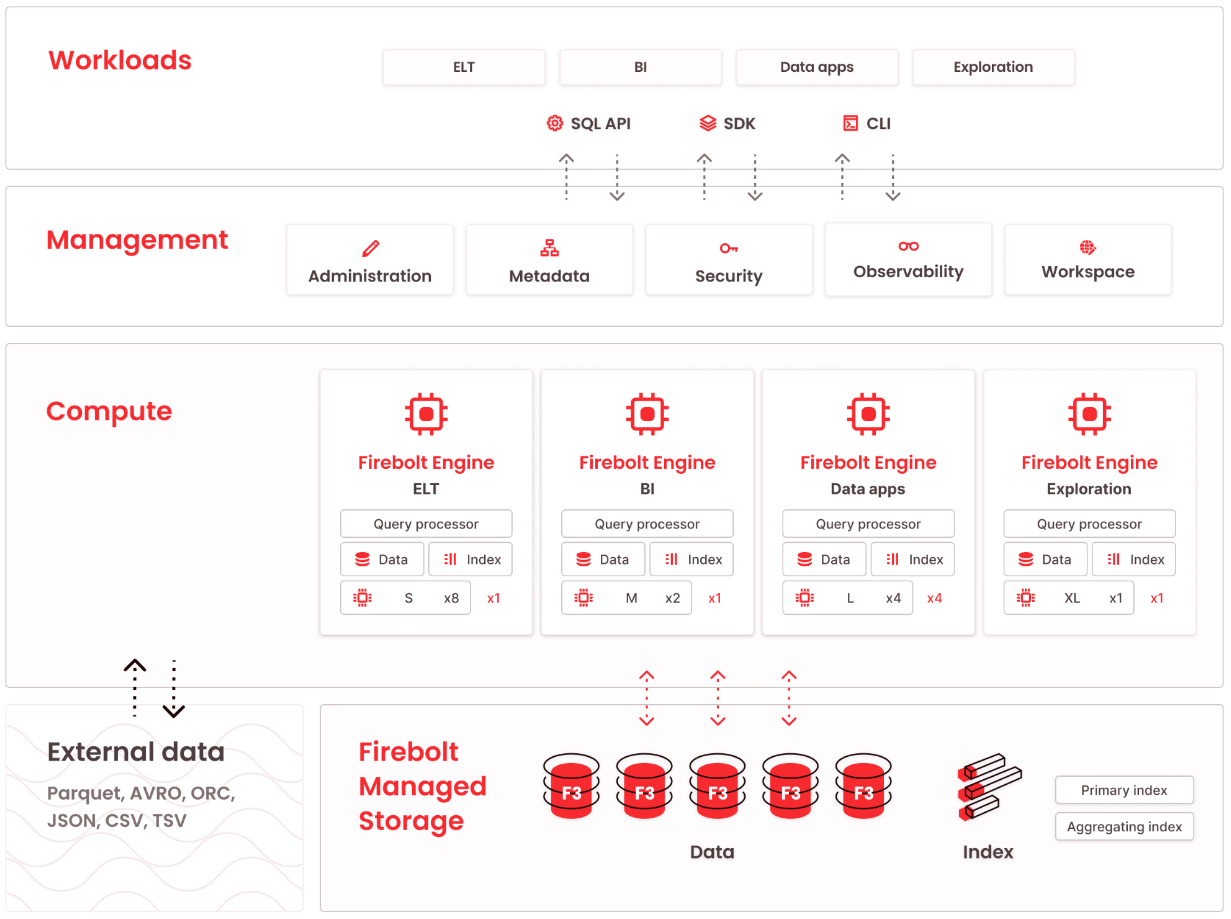
上图是Firebolt的架构,它包括:
- 服务层,服务层是多租户的。它接受Firebolt的所有传入请求。它最重要的功能是:
- 管理 - 处理帐户信息、用户管理和权限。
- 元数据 - 包含所有数据库、引擎、表、索引等的元数据。
- 安全 - 处理身份验证。
- 隔离租户
与多租户服务层不同,Firebolt中的计算和存储层在隔离的租户上运行。为每个Firebolt客户创建一个专用的、隔离的AWS子帐户,在其中Firebolt管理存储和计算层。每个租户都在Firebolt的主帐户内运行,而不是在其自己的VPC中。这确保了数据和查询执行的完全跨客户隔离。 - 计算层
计算层运行Firebolt引擎。引擎是运行数据库工作负载的计算集群。每个引擎都是一个隔离的集群。在每个集群中,引擎节点将数据和索引存储在本地缓存中。引擎根据查询配置在查询运行时从存储层加载数据到缓存中。
存储计算分离的架构的好处是可以将多个引擎分配给同一个数据库。这允许对分配给哪些任务的硬件进行细粒度控制。每个引擎可以根据工作负载的不同配置和大小。引擎可以并行或分别工作,并且可以与组织中的不同人共享它们。
- 存储层
Firebolt中的存储层在Amazon S3上运行。在将数据摄入Firebolt后,与数据库相关的数据和索引保存在此处。在摄入数据时,使用Firebolt通用引擎,将数据存储在专有的Firebolt文件格式(F3)中。数据进行排序、压缩和索引,以支持高效的查询加速修剪。F3与其他专有的Firebolt技术一起,在查询运行时提供卓越的性能。
QUERY ENGINE
Firebolt引擎的设计遵循组件的经典分离,SQL解析器接受Firebolt的SQL方言,并将用户查询转换为抽象语法树(AST)。逻辑计划器然后将此AST转换为逻辑查询计划(LQP)。为了实现这一点,它使用逻辑元数据,如表和视图定义、数据类型和函数目录(catalog)。然后,计划器应用逻辑转换以生成优化的LQP。之后,Firebolt的物理计划器从LQP构建分布式查询计划(DQP)。为了实现这一点,它使用物理元数据,如索引的存在、表的基数和数据分布。分布式运行时协调Firebolt节点群中DQP的执行。其职责包括调度、阶段之间的数据交换和查询容错。最后,本地运行时在单个Firebolt节点内执行关系运算符。
SQL Dialect
云数据仓库并不是孤立存在的,它们是更广泛的数据生态系统的一部分。这个生态系统涵盖了ETL/ELT、BI、报告、数据科学、ML和数据可观察性工具。例如Fivetran、Dbt、Tableau、Looker和Monte-Carlo。随着用户在这些工具之上构建他们的应用程序,与更广泛的生态系统具有广泛的集成对于Firebolt的成功至关重要。幸运的是,上述所有工具都使用SQL与数据仓库通信。这极大地简化了与生态系统集成的过程。然而,仍然存在挑战。尽管存在ANSI SQL标准,但几乎每个数据库都具有自己的SQL方言。因此,上述工具需要各种自定义驱动程序、连接器和适配器来支持不同的数据库系统。要成为云数据仓库领域的成功创业公司并满足客户需求,从第一天开始与生态系统集成至关重要。作为一个小型创业公司,Firebolt不能指望生态系统工具背后的大公司花费时间和资源专门添加支持的自定义连接器和驱动程序。为了简化生态系统集成,我们决定Firebolt SQL方言应该类似于一个现有的、广泛采用的SQL方言。选择Postgres方言作为指引(north star)是一个容易的选择。它非常受欢迎,并且高度符合标准的ANSI SQL。因此,数据堆栈中几乎每个工具都支持Postgres SQL。需要注意的是,与Postgres SQL兼容并不意味着与Postgres wire协议兼容。Firebolt的驱动程序通过自定义基于HTTP的REST协议与Firebolt通信。
SQL Parser and Planner
Firebolt的SQL解析器需要与Postgres SQL非常相似。它必须完全覆盖DDL、DML和DCL语句。然而,对DQL(即SELECT)语句的支持是最重要的,因为它们占据了大部分工作负载。
我们希望将逻辑计划器基于一个现有的项目,满足广泛的要求。计划器需要支持现代数据仓库中最重要的规则,如谓词下推和子查询解耦。作为其中的一部分,该项目还需要具有基于规则的转换的可扩展框架。这将使我们能够在扩展产品时轻松添加Firebolt特定的规则。
除了基于规则的转换之外,计划器还需要支持基于成本的连接重排序。这包括允许我们构建自定义统计源和成本模型。考虑到Firebolt支持的不同索引类型的多样性,这一点尤为重要。例如,我们使用稀疏的主要和次要索引进行数据修剪,以及专门的索引用于频繁出现的广播连接。
最后,计划器需要支持复合数据类型,如数组和行(结构)类型。这些对面向用户、数据密集型应用程序非常流行,这也是Firebolt的目标。
可以分别选择不同的项目作为解析器和计划器的基线。然而,这两个组件共享一个非常复杂的接口:查询的AST离开解析器并进入计划器进行语义分析。我们决定优先考虑同时包含解析器和计划器的项目。幸运的是,有各种开源项目可以作为Firebolt的SQL解析器和计划器的基础。以下是这些项目的概述。
- Postgres解析器,考虑到我们希望符合Postgres SQL,直接使用Postgres解析器是显而易见的选择。这种方法已经在多个其他系统中成功使用(YugabyteDB,DuckDB)。将解析器与Postgres代码隔离开来是通过libpg_query项目1完成的。它将原始的基于C的Postgres解析器打包成一个库。
虽然这使得在Postgres解析器之上构建系统相对容易,但是在不引入大量Postgres代码库的情况下隔离计划器代码是困难的。对我们来说,这意味着选择Postgres虽然在解析层面几乎不需要投资,但需要大量的工作来构建符合我们需求的生产级计划器。 - ZetaSQL,ZetaSQL是Google2用C++构建的解析器和分析器。它是GoogleSQL的开源端口。GoogleSQL驱动云产品BigQuery、Spanner和Dataflow,以及Google内部产品Dremel、F1和Procella。它是一个干净构建、经过广泛测试和生产就绪的系统。然而,ZetaSQL提供了一种有争议的方言,与Postgres SQL在许多基本特性上存在分歧。此外,ZetaSQL仅支持基本的转换,没有功能丰富的计划器。
- Calcite,Apache Calcite是一个框架,为数据处理系统提供查询处理、优化和查询语言支持。它包括多个SQL方言的解析器和一个模块化、可扩展的查询计划器,支持可插拔规则。Calcite构建良好,经过了实战测试。它被用于许多知名的开源系统,如Apache Hive、Apache Storm、Apache Flink、Druid和MapD3。
与我们考虑的其他用C++编写的替代方案相比,Calcite是用Java实现的。 - DuckDB,DuckDB是一种内存中、进程内的分析数据库系统,起源于CWI。它经过广泛测试,广泛用于交互式数据分析。DuckDB的查询计划器支持基于规则的优化和基于成本的连接重排序。DuckDB使用libpg_query项目作为其解析器的基线,提供Postgres SQL兼容性。现在,DuckDB将其解析器移植到了C++。当我们决定基于哪个项目构建我们的解析器和计划器时,DuckDB还不够成熟。
- Hyrise,Hyrise是在HPI开发的内存数据库。它具有相对简单的代码库,易于重构和扩展。与DuckDB类似,它支持基于规则的优化和基于成本的连接重排序。
然而,作为一个学术项目,Hyrise没有经过实战测试,也没有广泛的SQL覆盖。
我们早期决定希望计划器和运行时使用相同的编程语言编写。我们认为这不是构建新系统时的硬性要求。有多个使用基于JVM的计划器和用C++编写的高性能运行时的成功系统。然而,我们认为使用同一种语言编写引擎可以使我们作为初创公司具有高速度。数据库系统中的许多工作都发生在计划器和运行时的交集处。对于Firebolt来说,这尤其正确,因为我们必须集成来自不同开源项目的两个组件。计划器和运行时使用相同的编程语言,使开发人员可以在最小的上下文切换下跨越整个堆栈工作。由于我们决定使用C++编写运行时,我们希望计划器也遵循这个选择。这让我们面临选择Hyrise或DuckDB的问题。我们决定基于Hyrise项目构建,因为它简单易扩展。在将Firebolt准备好投入生产时,Hyrise是一个学术系统,SQL支持有限,这证明是一个挑战。对于今天构建新数据库系统的工程师来说,使用DuckDB可能是更好的起点,因为自从我们开始构建Firebolt以来,DuckDB已经显著成熟并广泛使用。
同时,对于我们的用例,使用Hyrise确实是一个不错的选择。事实证明,我们最初选择它是因为它相对简单。我们大力投资使Firebolt的解析和计划层准备投入生产。现在,它在Hyrise的开源根源已经难以辨认。我们的添加包括广泛扩展解析器以提供良好的SQL覆盖率和对计划层的重大更改。我们增加了对复合数据类型的广泛支持,改变了逻辑查询计划的表示方式,使其更容易构建基于规则的优化,并添加了各种新规则到计划器中。
我们对逻辑查询计划的重新设计受到Calcite的启发。作为可扩展和功能丰富的开源查询计划器的黄金标准,我们决定利用Calcite的关系代数表示中发现的许多概念。这使得我们的计划器在新的SQL功能和优化能力方面具有未来的保障和可扩展性。
Runtime
运行时是查询引擎的核心。它负责查询评估,并必须实现数据类型、函数和关系运算符,如连接和聚合。与解析和计划层类似,Firebolt可以选择从头开始构建新的查询引擎,或者从现有的开源项目中引导一个查询引擎。许多数据库公司决定从头开始构建运行时。例如,CockroachDB、Databricks和Snowflake。我们认为,为了作为一个小型初创公司打破数据仓库领域,最好选择从现有的代码库开始,并将相对有限的工程资源分配给Firebolt的独特差异化特性。在决定使用哪个项目作为我们运行时的基线时,我们有一些基本的保障措施。
为了支持面向用户、数据密集型应用程序,我们需要一个高性能的查询引擎,允许低延迟的查询处理。构建高性能运行时有两种现代方法——向量化和代码生成。我们决定要在向量化运行时的基础上构建Firebolt。虽然构建低延迟的代码生成引擎是可能的,但它需要大量投资到先进的编译堆栈。这增加了引擎的复杂性,使新工程师的入职更加困难,并降低了开发速度。同时,代码生成和向量化引擎在OLAP工作负载方面的性能通常相似。
我们还希望引擎具有鲁棒性,并具有分布式数据处理的基本支持。虽然有各种有趣的学术和实验性开源查询引擎,但其中许多不具备生产就绪性或不支持分布式查询执行。从一个经过实战测试和横向可扩展的引擎开始,可以快速组装一个强大的查询引擎,可以处理海量数据集。
除了运行时,我们还希望引导我们的存储引擎,特别是文件格式。为了构建高性能的查询引擎,存储引擎使用列式数据布局以有效地支持OLAP工作负载是必不可少的。当引导查询运行时和存储引擎时,所面临的挑战与引导解析器和计划器时相似。可以分别选择不同的系统作为存储引擎和查询运行时的基线。然而,两个组件共享复杂的接口,以便在层之间传输数据并促进数据修剪。因此,选择一个项目来提供这两个组件使得构建高性能系统变得更加容易。
虽然有多个项目可供选择作为SQL解析器和计划器的基线,但在选择高性能的分布式运行时时可选项较少。我们很快将选择范围缩小到ClickHouse。
ClickHouse旨在快速运行,这些声明得到了基准测试的支持。ClickHouse使用矢量化查询执行,并通过LLVM提供有限的运行时代码生成支持。ClickHouse经过实战测试,在生产环境中被广泛使用。最后,ClickHouse还有自己的列式文件格式称为MergeTree。MergeTree与查询运行时紧密集成,允许有效的数据修剪。所有以上原因使得选择ClickHouse作为Firebolt运行时的基础变得容易。
Connecting Planner and Runtime
Firebolt集群中的每个节点都可以作为查询协调器运行解析器和计划器,并作为运行时工作器执行更大查询计划的部分。当查询进入系统时,它被路由到其中一个节点。然后,该节点充当协调器。在查询解析和计划之后,它需要启动查询执行。Firebolt LQP直接转换为分布式查询计划。然后,这个分布式查询计划被分解成多个阶段。协调器将阶段发送到Firebolt集群中的不同工作节点,以促进分布式查询执行。对于跨网络通信,我们使用自定义的基于protobuf的序列化格式。在工作节点上,这个序列化格式用于组装运行时的矢量化关系运算符。在未来,Substrait可能是使用自定义序列化格式的可行替代方案。然而,Substrait仍在快速发展中,并且可能会发生重大变化。
这里很奇怪的设计是,每个Node既可以做Coordinator也可以做Worker,而不是其它云数仓那种分离的架构,比如snowflake的cloud service & virtual warehouse。
Distributed Execution
在选择ClickHouse作为Firebolt运行时的基础之后,我们最初也利用了ClickHouse的分布式查询处理方法。ClickHouse中的分布式查询处理对于某些查询形状非常有效。例如,具有选择性表扫描、低基数分组字段的分布式聚合和广播连接的查询。同时,ClickHouse不支持许多在数据仓库中常见的重要SQL模式,例如两个大型关系之间的连接、高基数分组字段的聚合、没有粒度PARTITION BY子句的窗口函数和大型分布式排序。
我们决定完全摆脱ClickHouse的分布式执行堆栈,以更好地服务于我们客户的数据密集型工作负载。为此,我们实现了一个新的Firebolt分布式处理堆栈。我们计划器返回的优化LQP被分解成通过Shuffle运算符连接的阶段。通过扩展,这使我们能够执行我们原始运行时难以处理的查询。例如,具有高基数聚合或两个大表的连接的查询。我们将在未来的出版物中分享更多关于我们分布式处理堆栈的信息。
实现这个新的分布式处理堆栈只有在我们早期决定我们的运行时应该是ClickHouse的硬分叉时才有可能。这使我们能够灵活地重构接口、改变系统的整体架构,并构建一个针对我们客户需求进行优化的运行时。
TESTING
构建软件不仅仅是编写代码。它还涉及确保代码正常工作。对于数据库系统来说,这尤其重要。用户信任我们的数据,并依赖我们产生正确的查询结果。这不是一件轻松的事情。
虽然我们在编写自己的测试用例方面投入了大量精力,但我们只手工制作了其他地方可用的测试用例的一小部分。幸运的是,在集成开源测试用例时,您不必在不同的测试套件和框架之间进行选择。相反,您可以使用多个不同的测试套件来结合它们各自独特的优势。
在Firebolt中,我们的目标是实现最大覆盖范围,并从任何地方获取测试用例。这意味着许多测试用例由于各种原因未能通过。SQL方言的差异、功能的差异、未指定的行为等等,使得从其他框架移植测试用例并让它们“正常工作”变得困难。然而,与多样化的开源测试套件集成帮助我们识别真正的问题。通过通过测试,确保我们不会在功能或正确性方面出现退化。
Firebolt Query Verification Framework
大多数SQL查询测试框架都遵循类似的模式-它们基于一个或多个测试文件,概述了数据流。首先,可以使用SQL DDL查询定义模式。然后,SQL DML查询将表与数据关联。最后,运行实际测试的SQL查询。这些大多是SELECT语句。它们的结果与预定义的预期结果进行检查。
我们构建了一个名为“PeaceKeeper”的自定义测试框架,遵循类似的模式。PeaceKeeper知道如何在多个环境中设置Firebolt集群。这些可以是在开发人员机器上的本地运行,允许快速迭代,CI管道,或者是云中强大的分布式SQL集群。PeaceKeeper使用带有输入查询和预期结果的测试文件。我们已经实现了2K+ Firebolt特定的SQL查询测试用例。
Clickhouse Functional Tests
考虑到我们的运行时是基于ClickHouse构建的,自然而然地集成了ClickHouse提供的30K+功能测试。然而,由于ClickHouse SQL方言与Firebolt的SQL方言非常不同,这些测试无法通过我们的整个查询流程。相反,它们直接针对运行时工作。我们正在弃用这些测试用例,因为分布式执行堆栈不再与CickHouse SQL解析层集成。
Postgres Regression Tests
由于Firebolt力求尽可能接近Posgres SQL,因此重用Postgres测试套件是有意义的。它在其回归套件中有12K+个测试。并非所有的Postgres结构都受到Firebolt的支持。然而,对于Firebolt支持的那些结构,我们能够验证Firebolt的行为与Postgres相同。这是通过一个自动化脚本完成的,该脚本将Postgres回归测试转换为PeaceKeeper格式。
ZetaSQL Compliance Tests
ZetaSQL在其合规性测试套件中有60K+个测试。ZetaSQL合规性测试的独特之处在于,很大一部分测试用例都集中在SQL表达式和单个函数上,广泛涵盖不同的边界条件-这是许多其他测试套件只是粗略地做的事情。ZetaSQL的合规性测试大多是基于代码而不是基于文件的。为了保持我们的测试工具一致,我们编写了一个翻译程序来捕获PeaceKeeper格式的测试查询。
SQLLogicTest
功能性SQL测试的巅峰是SQLLite的SQLLogicTest框架。它包含7M+个测试查询(即700万个!)。我们再次编写了一个脚本,将SQLLogicTests转换为PeaceKeeper格式。DuckDB也采用了类似的方法。由于查询的数量非常庞大,我们仍在处理每个单独的结果并解决错误的过程中。
LESSONS LEARNED
- 选择坚实的基础
特别是对于查询解析器和计划器,可以使用各种成熟的项目作为基线。虽然我们发现Hyrise是一个很好的基础,并且对我们当时做出的选择感到满意,但我们建议今天组装新系统的工程师使用DuckDB或Calcite。虽然在高性能分布式运行时方面选择较少,但我们发现ClickHouse是一个强大且可扩展的基础。在构建生产系统时,我们建议选择经过实战考验的项目作为起点。
- 使用单一语言构建
使用单一编程语言编写的项目组装系统可以提高开发速度。这在初创企业的早期阶段尤其如此,因为开发人员可能需要经常在不同的组件之间切换或在整个堆栈上构建功能。
- 连接不同的系统
当选择不同的系统(例如计划器和运行时)时,工程团队需要大量投入到构建这些组件之间的清晰接口。当基于不同的项目构建解析器和计划器,或运行时和存储引擎时,我们预计会产生类似的影响。因此,我们建议尽可能选择尽可能少的系统来组装新的数据库管理系统。
在Firebolt中,我们只选择了两个用相同编程语言编写的系统。将它们连接并将它们转变为生产就绪的系统仍需要大量的工作。将系统越来越接近需要协同努力,这仍在进行中。新分布式执行堆栈就是一个例子。但是还有很多工作要做。一个很好的例子是统一计划器和运行时的类型系统。我们认为,从头开始构建新系统的主要好处是不必集成差异很大的项目,这可能有些令人惊讶,Apache Arrow项目在组合Firebolt的查询引擎时并没有发挥重要作用。许多现有的开源项目使用Arrow将数据传输到系统中并将其传输出来。在Firebolt中,所有数据传输都发生在运行时的分布式原语内部,以及从运行时返回数据到用户时。因此,我们不需要与Arrow集成,例如促进跨项目数据传输。我们预计,随着Arrow和相关项目在开源项目中的广泛采用,从不同组件组装数据库系统将变得更加容易。
- 测试系统
我们建议尽早与尽可能多的测试框架集成。虽然这在开始时可能看起来很费力,但从长远来看会得到回报。它允许团队快速捕捉目标SQL方言中的潜在兼容性问题,以及与其他系统相比运行时行为的微妙差异。然而,筛选测试用例失败以确定哪些指向潜在问题,哪些是更温和的,需要花费大量时间。
| SQL Dialect and Parser | Planner | Single-Node Runtime | Distributed Execution | |
|---|---|---|---|---|
| Inspired By | Postgres | Calcite | ||
| Based On | Hyrise | Hyrise | Clickhouse | Firebolt |
| Tested By | ZetaSQL Compliance Tests Postgres Regression Tests |
ZetaSQL Compliance Tests Postgres Regression Tests |
ZetaSQL Compliance Tests Postgres Regression Tests |
|
| SQLite SQLLogicTest | SQLite SQLLogicTest | SQLite SQLLogicTest | SQLite SQLLogicTest |