Velox Primer 1,2,3
Velox Primer 1,2,3
作者:Orri Erling · Pedro Pedreira(Meta Software Engineers) 原文: https://velox-lib.io/blog/velox-primer-part-1 | part-2 | part-3
第一篇:分布式查询执行基础
发表于:2025 年 2 月 17 日
本文是系列短文的第一篇,将带你了解 Velox 的内部结构和核心概念。在这一篇中,我们将讨论分布式查询如何执行、数据如何在不同阶段之间进行 Shuffle,并介绍 Task、Split、Pipeline、Driver 和 Operator 等 Velox 核心概念。
分布式查询执行
Velox 是一个库,提供分布式计算引擎中查询片段(Query Fragment)所需的各种功能。Presto 和 Spark 等分布式计算引擎运行所谓的交换并行计划(Exchange Parallel Plans)。Exchange 也称数据 Shuffle,允许数据从一个阶段流向下一个阶段。查询片段是由 Shuffle 连接起来的处理单元,包含在单个 Worker 节点内执行的处理逻辑。Shuffle 接收一组片段的输入,并根据数据的某种特征(即分区键)将输入行路由到特定的消费者。Shuffle 的消费者从 Shuffle 中读取数据,获取分区键与之匹配的行。
以下面的查询为例:
SELECT key, count(*) FROM T GROUP BY key
假设有 n 个叶子片段扫描 T 的不同部分(阶段 1 的绿色圆圈)。在叶子片段末尾,假设有一个基于 key 对行进行 Shuffle 的交换操作。有 m 个消费者片段(阶段 2 的黄色圆圈),每个消费者获取基于 key 列的不重叠行子集。每个消费者随后构建一个以 key 为键的哈希表,记录特定 key 值出现的次数。
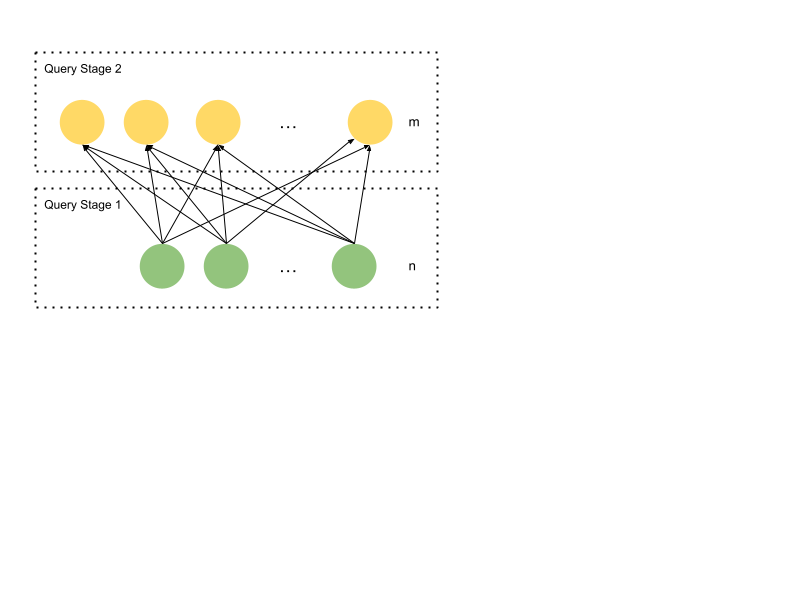
如果 key 有 1000 亿个不同值,哈希表将无法方便地放入单台机器。出于效率考虑,将其划分为 100 个各含 10 亿条目的哈希表是有意义的——这正是交换并行横向扩展的意义所在。可以将 Shuffle 理解为:让每个消费者消费由多个 Worker 产生的大型数据流中属于自己的那一不重叠片段。
Presto 和 Spark 等分布式查询引擎都符合上述描述,区别在于(除其他之外)它们如何执行 Shuffle,这一点后续再讨论。
Task 和 Split
在 Worker 节点内部,Velox 对查询片段的表示称为 Task(velox::exec::Task)。一个 Task 主要由两部分信息确定:
- 计划(Plan) -
velox::core::PlanNode:指定 Task 执行什么。 - Split -
velox::exec::Split:指定 Task 操作的数据。
Split 与 Task 正在执行的计划相对应。对于第一阶段的 Task(表扫描),Split 指定要扫描的文件片段;对于第二阶段的 Task(Group By),其 Split 标识 Group By 从中读取输入的表扫描 Task。Split 分为两类:文件 Split(velox::connector::ConnectorSplit)标识要读取的数据,远程 Split(velox::exec::RemoteConnectorSplit)标识一个正在运行的 Task。
分布式引擎生成 PlanNode 和 Split,Velox 接收这些并创建 Task。Task 向分布式引擎反馈统计信息、错误和其他状态。
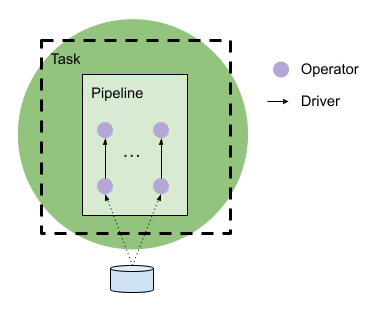
Pipeline、Driver 和 Operator
在 Task 内部,有若干 Pipeline。每个 Pipeline 是一个算子(velox::exec::Operator)的线性序列,算子是实现关系逻辑的对象。以前述 Group By 示例为例,第一个 Task 有一个 Pipeline,包含 TableScan(velox::exec::TableScan)和 PartitionedOutput(velox::exec::PartitionedOutput)。第二个 Task 同样有一个 Pipeline,包含 Exchange、LocalExchange、HashAggregation 和 PartitionedOutput。
每个 Pipeline 有一个或多个 Driver。Driver 是一个线性 Operator 序列的容器,通常在自己的线程上运行。Pipeline 是具有相同 Operator 序列的 Driver 的集合,各个 Operator 实例属于每个 Driver,Driver 属于 Task,这些通过智能指针互相链接,在需要时保持存活。
包含两个 Pipeline 的 Task 的例子是哈希 Join,Build 侧和 Probe 侧各有独立的 Pipeline——这是合理的,因为必须在 Probe 可以进行之前完成 Build。后续会对此进行更多讨论。
每个 Driver 上的算子通过 Driver 相互通信:Driver 从一个算子获取输出,记录统计信息,并将输出传递给下一个算子。算子之间传递的数据是向量(Vector)。具体来说,算子产生/消费 RowVector,RowVector 是每列都有一个子向量的向量——它相当于 Arrow 中的 RecordBatch。所有向量都是 velox::BaseVector 的子类。
算子的数据源、数据汇和状态
Driver 中的第一个算子称为数据源(Source)。Source 算子通过 Split 确定提供数据的文件/远程 Task,并产生一系列 RowVector。Pipeline 中的最后一个算子称为数据汇(Sink)。Sink 算子不产生输出的 RowVector,而是将数据放到某处供消费者获取,通常是 PartitionedOutput。PartitionedOutput 的消费者是另一个 Task 中的 Exchange,其中 Exchange 处于 Source 位置。既非 Source 也非 Sink 的算子有 FilterProject、HashProbe、HashAggregation 等,后续将详细介绍。
算子还包含状态:可以是阻塞中、接受输入、有输出可产生或无输出可产生,以及被通知不会再有更多输入。算子不直接调用其他算子的 API 函数,而是由 Driver 决定下一步推进哪个算子。这样做的好处是,Driver 的状态不会被捕获在嵌套函数调用中——Driver 有一个扁平的调用栈,因此可以在任何时候上下线程,无需展开和恢复嵌套函数帧。
小结
我们了解了分布式查询如何由通过 Shuffle 连接的片段组成。每个片段有一个 Task,Task 包含 Pipeline、Driver 和 Operator。PlanNode 表示 Task 应该做什么,告诉 Task 如何设置 Driver 和 Operator。Split 告诉 Task 在哪里找到输入(如从文件或其他 Task)。Driver 对应一个执行线程,可能处于运行或阻塞状态(如等待数据可用,或等待消费者消费已产生的数据)。算子之间以向量形式传递数据。
下一篇文章我们将讨论查询生命周期的不同阶段。
第二篇:从计划到 Driver 和 Operator
发表于:2025 年 3 月 25 日
在本文中,我们将讨论分布式计算引擎如何执行与第一篇文章中类似的查询:
SELECT l_partkey, count(*) FROM lineitem GROUP BY l_partkey;
我们使用 TPC-H Schema 来说明示例,以 Prestissimo 作为编排分布式查询执行的计算引擎。Prestissimo 负责查询引擎的前端(解析、元数据解析、规划、优化)和分布式执行(分配资源和分发查询片段),Velox 负责在单个 Worker 节点内执行计划片段。本文将说明哪些功能由 Velox 执行,哪些由分布式引擎(本例中为 Prestissimo)执行。
查询初始化
Prestissimo 首先通过 Coordinator 节点接收查询,Coordinator 负责解析和规划查询。对于我们的示例查询,将创建包含三个查询片段的分布式查询计划:
- 第一个片段从 lineitem 表读取
l_partkey列,并根据l_partkey的哈希值划分输出。 - 第二个片段读取第一个片段的输出,并更新一个以
l_partkey为键的哈希表,记录特定l_partkey值出现的次数(count(*)聚合函数的实现)。 - 最终片段在第二个片段收到来自第一个片段的所有行后,读取哈希表的内容。
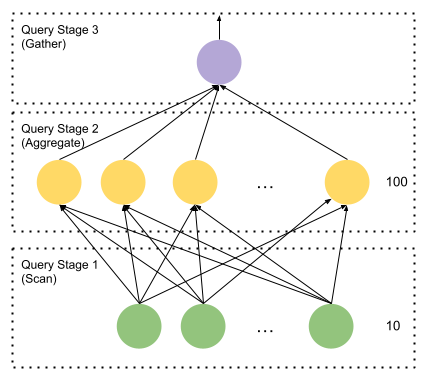
两个前序片段之间的 Shuffle 根据 l_partkey 对数据进行分区。假设第二个片段有 100 个实例:如果 l_partkey 的哈希值对 100 取模为 0,则该行进入第二阶段的第一个 Task;为 1 则进入第二个 Task,以此类推。这样每个第二阶段的 Task 获得不重叠的行子集。第二和第三阶段之间的 Shuffle 是归并(Gather),意味着第三阶段只有一个 Task,它读取所有 100 个第二阶段 Task 的输出。
Stage 是共享同一计划片段的 Task 集合。Task 是 Prestissimo 与 Velox 的主要集成点,是在 Stage 内物理处理所有或部分数据的 Velox 执行实例。
在设置分布式执行时,Prestissimo 首先从它管理的 Prestissimo 服务器进程池中选择 Worker。假设第一阶段有 10 个 Worker,它选择 10 个服务器进程并向它们发送第一阶段计划,然后为第二阶段选择 100 个 Worker 并发送第二阶段计划。汇聚结果的最后阶段只有一个 Worker,因此 Prestissimo 只向一个 Worker 发送最终计划。每个阶段的 Worker 集合可以重叠,因此单个 Worker 进程可以承载同一查询的多个阶段。
Task 初始化
在 Prestissimo 中,设置 Worker 中 Task 的消息称为 Task Update。Task Update 包含以下信息:计划、配置项,以及可选的 Split 列表。Split 还会标注它们针对的是哪个计划节点,以及该接收方计划节点和 Split 组是否还有更多 Split 即将到来。
由于 Split 的生成涉及从存储枚举文件(可能需要一些时间),Presto 允许以异步方式将 Split 发送给 Worker,这样 Split 的生成可以与第一批 Split 的执行并行进行。因此,第一次 Task Update 指定计划和配置,后续的 Task Update 只添加更多 Split。
除计划之外,Coordinator 还以字符串键值对映射的形式提供配置,包括顶层配置和 Connector 级别的配置。Connector 配置为每个 Connector 提供设置;Connector 由表扫描和表写入操作使用,用于处理存储和文件格式。这些配置及其他信息(如线程池、顶层内存池等)通过 QueryCtx 对象传递给 Task。详见 Velox 仓库中的 velox/core/QueryCtx.h。
从计划到 Driver 和 Operator
一旦 Velox Task 创建完成,TaskManager 就会向其传入需要处理的 Split,通过 Task::addSplit() 完成,可以在 Task 开始执行后进行。详见 velox/exec/Task.h。
让我们深入了解 Task 创建时发生了什么:指定 Task 执行内容的 PlanNode 树作为 PlanFragment 的一部分传给 Task。Task 创建时最重要的步骤是将计划树拆分为 Pipeline。每个 Pipeline 然后获得一个 DriverFactory,DriverFactory 是为 Pipeline 创建 Driver 的工厂类。Driver 依次包含运行查询工作的 Operator。DriverFactory 在 LocalPlanner.cpp 中创建,详见 LocalPlanner::plan。
遵循 Volcano 执行模型,计划由算子树表示,每个节点消费其子算子的输出并将输出返回给父算子。根节点通常是 PartitionedOutputNode 或 TableWriteNode。叶节点是 TableScanNode、ExchangeNode 或 ValuesNode(用于查询字面量)。完整的 Velox PlanNode 集合可在 velox/core/PlanNode.h 中找到。
PlanNode 大多数情况下与 Operator 一一对应。PlanNode 本身不可执行,它们只是描述如何创建 Driver 和 Operator 的结构。如果节点树只有一个分支,则计划是单一 Pipeline;如果节点有多个子节点(输入),则第二个输入成为独立的 Pipeline。
Task::start() 创建 DriverFactory,DriverFactory 再创建 Driver。为启动执行,Driver 被加入线程池执行器的队列。运行 Operator 的主函数是 Driver::runInternal()。该函数中有 Operator 和 Driver 接口的详细交互:
Operator::isBlocked()判断 Driver 是否可以推进。如果不能,Driver 会离开线程,直到某个 Future 被实现,Future 再将其放回执行器。getOutput()从 Operator 获取数据,addInput()向另一个 Operator 喂入数据。- 执行顺序是推进能产出输出的最后一个 Operator,然后将其输出喂给下一个 Operator。如果 Operator 无法产出输出,则对它之前的 Operator 调用
getOutput(),直到找到能产出数据的一个。如果没有 Operator 阻塞且没有 Operator 能产出输出,则计划执行结束,每个 Operator 上都调用noMoreInput()——这可以解除结果产出的阻塞,例如 OrderBy 只有在知道已获得所有输入后才能产出输出。
最简 Pipeline:表扫描与重分区
表扫描。 对于示例查询的表扫描阶段,有一个包含两个算子的 Pipeline:TableScan 和 PartitionedOutput。假设该 Pipeline 有五个 Driver,所有五个 Driver 都进入线程池执行器队列。PartitionedOutput 因为没有输入什么都做不了,于是调用 TableScan::getOutput(),详见 velox/exec/TableScan.cpp。
TableScan 的第一个动作是调用 task::getSplitOrFuture() 查找 Split。如果没有可用的 Split,这会返回一个 Future;Driver 随后将自己停在线程外,并在 Future 上安装一个回调,当 Split 可用时重新调度 Driver。
也有可能没有 Split,且 Task 已被通知不会再有更多 Split,此时 TableScan 执行结束。如果 Split 可用,TableScan 将解释它:根据计划中提供的 TableHandle 规格(列和过滤器列表),Connector(如 Split 中所指定)创建一个 DataSource。DataSource 处理 IO 以及文件和表格式的细节,之后 Split 被传给 DataSource,然后可以反复调用 DataSource::next() 获取 Split 所指定的文件/文件段的向量(批次)输出。如果 DataSource 执行结束,TableScan 查找下一个 Split。Connector 和 DataSource 的接口详见 Connector.h。
重分区。 至此,我们已追踪到 TableScan 返回其第一批输出。Driver 将其喂给 PartitionedOutput::addInput(),详见 PartitionedOutput.cpp。
PartitionedOutput 首先对分区键(本例中为 l_partkey)计算哈希,为输入 input_(RowVectorPtr 批次)中的每行产生一个目标编号。每个目标有一个部分填充的序列化缓冲区(VectorStreamGroup)。如果第二阶段有 100 个 Task,每个 PartitionedOutput 有 100 个目标,每个目标一个 VectorStreamGroup。VectorStreamGroup 的主要函数是 append(),接收 RowVectorPtr 和其中一组行号,将行号标识的每个值序列化并添加到部分形成的序列化结果中。当 VectorStreamGroup 中积累了足够多的行时,产生一个 SerializedPage,详见 PartitionedOutput.cpp 中的 flush()。
SerializedPage 是一个自包含的序列化信息包,可以通过网络传输到下一阶段,每个这样的数据包只包含发往同一接收方的行。这些数据包随后在 Worker 进程的 OutputBufferManager 中排队。注意 flush() 中带有 BlockingReason 的代码——缓冲区管理器为所有 Task 的所有消费者维护独立的队列。如果队列已满,添加输出可能会阻塞,这会返回一个在有空间添加更多数据时被实现的 Future,这取决于 Task 的消费者 Task 何时获取数据。
Prestissimo 中的 Shuffle 由生产者端的 PartitionedOutput 和消费者端的 Exchange 实现。OutputBufferManager 保存供消费者获取的序列化好的数据。这些数据与 Presto 线协议的绑定在 TaskManager.cpp(生产者端)和 PrestoExchangeSource.cpp(消费者端)中。
小结
我们介绍了计划如何变得可执行,以及数据如何在算子之间和内部流动。我们讨论了 Driver 可以阻塞(离开线程)以等待 Split 变得可用,或等待其输出被消费。目前我们只浅尝了运行分布式查询叶子阶段的皮毛,但算子和向量还有更多内容。在下一篇 Velox Primer 文章中,我们将了解示例查询的第二阶段做什么。
第三篇:Shuffle 消费、字典魔法与聚合屏障
发表于:2025 年 5 月 12 日
在上一篇文章结束时,我们的第一个分布式查询已经执行到一半:
SELECT l_partkey, count(*) FROM lineitem GROUP BY l_partkey;
我们讨论了查询如何启动、Task 如何设置,以及计划、算子和 Driver 之间的交互。我们也展示了查询第一阶段如何执行——从表扫描到分区输出,即 Shuffle 的生产者侧。
本文将讨论第二查询阶段,即 Shuffle 的消费者侧。
Shuffle 消费者
如上一篇文章所述,在第一查询阶段,每个 Worker 读取表,然后产生一系列面向第二阶段不同 Worker 的信息数据包(SerializedPage)。在我们的示例中,lineitem 表没有特定的物理分区或聚簇键,这意味着表中任何文件的任意行都可能有任意 l_partkey 值。因此,为了按 l_partkey 分组数据,我们首先需要确保包含相同 l_partkey 值的行由同一个 Worker 处理——这正是第一阶段末尾数据 Shuffle 的目的。
整体查询结构如下:
查询 Coordinator 以无特定顺序将表扫描的 Split 分发给第一阶段的 Worker。
- Worker 处理这些 Split,并作为副作用填充将被第二阶段 Worker 消费的目标缓冲区。
- 假设有 100 个第二阶段 Worker,每个第一阶段的 Driver 都有自己的 PartitionedOutput,有 100 个目标。当缓冲的序列化数据增长到足够大时,它们被移交给 Worker 的 OutputBufferManager。
现在让我们聚焦到第二阶段的查询片段。每个第二阶段的 Worker 拥有如下计划片段:PartitionedOutput → Aggregation → LocalExchange → Exchange。
每个第二阶段的 Task 对应每个第一阶段 Worker 的 OutputBufferManager 中的一个目标。第一个第二阶段 Task 从所有第一阶段 Task 获取目标 0,第二个获取目标 1,以此类推。每个节点与其他所有节点通信,Shuffle 过程无需任何中心协调。
第二阶段开始时实际发生的事情:计划在 Exchange 之后有一个 LocalExchange 节点。这形成了两个 Pipeline:Exchange 和 LocalPartition 在一侧,LocalExchange、HashAggregation 和 PartitionedOutput 在另一侧。
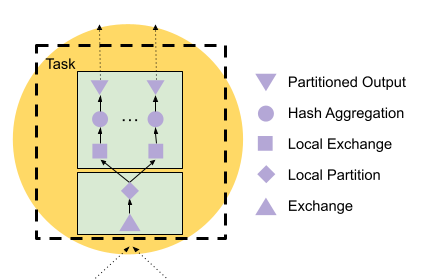
Velox Task 设计为多线程,通常有 5 到 30 个 Driver。每个阶段可能有数百个 Task,因此每个阶段有数千个线程。也就是说,100 个第二阶段 Worker 中的每个正在消费第一阶段总输出的 1/100,并以多线程方式进行,许多线程从 ExchangeSource 消费。
为了执行多线程 Group By,我们可以使用线程安全的哈希表,或将数据划分为 n 个不相交的流,然后在各自的线程上分别聚合。在 CPU 上,我们几乎总是倾向于让线程处理自己的内存,因此数据将基于 l_partkey 使用本地 Exchange 进行局部分区。CPU 有复杂的缓存一致性协议,对共享内存的一致有序视图进行协调既是必须的,也代价高昂;严格的内存-线程亲和性是让多核可扩展性正常工作的关键。
LocalPartition 和 LocalExchange
为了创建高效且独立的内存访问模式,第二阶段使用本地 Exchange 对数据进行二次 Shuffle。在概念上,这类似于 Task 之间的远程 Exchange,但局限在 Task 内部。生产者侧(LocalPartition)对分区列 l_partkey 计算哈希,并将其划分为消费者 Pipeline 中每个 Driver 对应一个目标。消费者 Pipeline 有一个 LocalExchange 源算子,从 LocalPartition 填充的队列中读取数据。详见 velox/exec/LocalPartition.h,以及 Task.cpp 中设置本地 Exchange 生产者和消费者之间队列的代码。
与使用序列化数据的远程 Shuffle 不同,本地 Exchange 在线程之间传递内存中的向量。这也是我们第一次遇到使用列式编码来加速向量化执行的概念。Velox 以广泛使用此类技术而闻名,我们将其称为压缩执行(Compressed Execution)。在这个实例中,我们使用字典将向量切片到多个目标——下面详细介绍。
字典魔法
查询执行通常需要改变数据的基数(结果中的行数)——这本质上就是过滤器和 Join 所做的事:过滤器或选择性 Join 降低数据基数,而有多个键匹配的 Join 则增加基数。
LocalPartition 中的重分区根据分区键为输入的每行分配一个目标,然后为每个目标创建一个只包含该目标行的向量。假设当前输入的第 2、8 和 100 行哈希到目标 1,目标 1 的向量应该只包含原始输入中的第 2、8 和 100 行。我们可以通过复制数据来创建一个包含三行的向量,但我们通过将原始输入的每列包装在一个长度为 3、索引为 2、8 和 100 的 DictionaryVector 中来省去复制操作。这比复制高效得多,对于宽表和嵌套数据尤为如此。
之后,运行目标 1 的 LocalExchange 消费者线程将看到一个 3 行的 DictionaryVector。当 HashAggregation 算子访问这个向量时,聚合将通过间接索引访问:对第 0 行访问基础(内部)向量中索引 2 处的值,对第 1 行访问索引 8 处的值,以此类推。目标 0 的消费者做完全相同的事,但可能访问第 4、9 和 50 行。
所有消费者线程的字典基础向量是相同的。每个消费者线程只查看不同的子集。各核读取相同的缓存行,但由于基础向量不被写入(只读),不会产生缓存一致性开销。
总结一下,DictionaryVector<T> 是对任意 T 类型向量的包装,DictionaryVector 指定索引,这些索引给出进入基础向量的下标。字典编码通常在列中不同值很少时使用。比如字符串 "experiment" 和 "baseline":如果某列只有这两个值,将其表示为在位置 0 放 "experiment"、位置 1 放 "baseline" 的向量,以及一个有 1000 个元素(每个都是索引 0 或 1)的 DictionaryVector,效率远高于直接存储 1000 个字符串。
除此之外,DictionaryVector 还可以用来表示基础元素的子集或重排序。因为所有接受向量的地方也接受 DictionaryVector,DictionaryVector 成为了表示选择操作的通用方式。这是 Velox 和其他现代向量化引擎的核心原则,我们会经常遇到这个概念。
聚合与 Pipeline 屏障
我们现在到达了第二阶段的第二个 Pipeline,从 LocalExchange 开始,然后进入 HashAggregation。LocalExchange 选取其本地目标对应的 Task 输入的一部分,大约是 Task 输入的 1/Driver 数量。
我们将在后续文章中讨论哈希表的具体布局和其他技巧。现在,我们将 HashAggregation 视为黑盒。这个特定的聚合是最终聚合(Final Aggregation),是一个完整的 Pipeline 屏障(Pipeline Barrier),只在接收所有输入后才产出输出。
聚合如何知道它已经收到了所有输入?让我们追踪完成信号在 Shuffle 中的传播过程:
叶子 Worker 如何知道结束: 如果 Task 从 Coordinator 收到了最后一次 Task Update 中的"不会再有更多 Split"消息,叶子 Worker 就知道已到结束。因此,如果 TableScan 内的某个 DataSource 执行结束,且没有更多 Split,则该 TableScan 不再阻塞且已到结束——Driver 会在 TableScan 的 PartitionedOutput 上调用 noMoreInput(),这会导致任何目标的缓冲数据被刷新并移交给 OutputBufferManager,并附注"不会再有更多数据"。OutputBufferManager 知道 TableScan Pipeline 中有多少个 Driver,在收到这么多条"不会再有数据"消息后,它可以告知所有目标该 Task 不再为它们产生数据。
信号如何传播到第二阶段: 当第二阶段的 Task 查询第一阶段的生产者时,当所有生产者都发出"不会再有数据"的信号后,它们就知道已到结束。获取目标数据请求的响应中有一个标识最后一批的标志。第二阶段 Task 的 ExchangeSource 设置"无更多数据"标志,所有 Driver 查询此标志,每个 Exchange 算子看到这个标志后在 LocalPartition 上调用 noMoreInput(),这会在本地 Exchange 队列中排队一个"无更多数据"信号。如果第二阶段第二个 Pipeline 开头的 LocalExchange 从其每个数据源都看到了"无更多数据",它就到达结束,并在 HashAggregation 上调用 noMoreInput()。
这就是数据结束信号的传播方式。在此之前,HashAggregation 没有产出任何输出,因为在收到所有输入之前,计数是未知的。现在,HashAggregation 开始产出包含 l_partkey 值和该值出现次数的输出批次。这些到达最后的 PartitionedOutput,在本例中它只有一个目标——产生最终结果集的那个 Worker。该 Worker 在所有 100 个数据源都报告了各自的数据结束后,才会到达结束。
小结
我们终于完整走完了一个简单查询的分布式执行过程。我们介绍了数据如何在集群的 Worker 之间分区,以及在每个 Worker 内部如何再次分区。
Velox 和 Presto 的设计是积极并行化执行——这意味着在每个线程上创建不重叠的数据子集来处理。线程越多,吞吐量越高。同时要记住,CPU 线程要高效,必须处理足够大的任务(通常超过 100 微秒的 CPU 时间),并且不要与其他线程过多通信,也不要写入其他线程正在写入的内存——这通过本地 Exchange 来实现。
本文另一个重要收获是:列式编码(特别是 DictionaryVector)如何作为表示选择/重排序/复制的零拷贝方式。我们将在过滤器、Join 和其他关系操作中再次看到这种模式。
下一篇,我们将深入研究 Join、过滤器和哈希聚合,敬请期待!
标签: tech-blog · primer