Velox: Meta’s Unified Execution Engine

What is Velox
Velox是Meta开发的扩展性强,高性能的C++执行引擎加速库,提供可重用、可扩展、高性能且与方言无关的数据处理组件,用于构建执行引擎和增强数据管理系统。该库在很大程度上依赖向量化和适应性,并从根本上设计为支持对复杂数据类型的高效计算,因为这些类型在现代工作负载中非常普遍。Velox被用于Meta内部的批处理,流处理,交互式查询,和机器学习组件(Presto, Spark, PyTorch, XStream, F3, FBETL等)。Velox不提供语言前端,比如SQL,Dataframe等,它使用一个充分优化后的查询计划作为输入,然后使用local host的资源执行。Velox虽然不提供全局优化器,但是它执行时应用了大量的自适应(adaptive)技术,比如filter,conjunct reordering, dynamic filter pushdown和adaptive column prefetching等,总而言之它主要关注数据面(data-plane),上层引擎(Presto,Spark等)主要负责控制面(control-plane)。Velox在以下方面提供了优势:
- 通过普及以前仅存在于个别引擎中的优化,提高效率
- 为数据用户提供更一致的体验
- 通过促进可重用性提高工程效率。
Why Velox
现代数据工作负载的多样性在不断增加,数据集指数级增长,导致了专门的查询和计算引擎的泛滥,每个引擎针对特定类型的工作负载。数据处理需求从简单的事务处理和分析(批处理和交互式),发展到ETL和大规模数据移动,再到实时流处理,以及用于监控用例的日志和时间序列处理,最近还包括大量的人工智能(AI)和机器学习(ML)用例,包括数据预处理和特征工程。这种演变导致了一个由数十个专门引擎组成的孤立数据生态系统,这些引擎使用不同的框架和库构建,彼此之间几乎没有共享,使用不同的编程语言编写,并由不同的工程团队维护。
此外,随着硬件和用例的演进,对这些引擎进行演进和优化的成本是不可接受的,如果按照每个引擎的方式进行。例如,将每个引擎扩展以更好地利用新的硬件进展,如高速缓存一致性加速器和非易失性内存(NVRAM),支持ML工作负载的张量数据类型等功能,并利用研究界未来的创新是不切实际的,这必然会导致具有不同优化和功能集的引擎。更重要的是,这种碎片化最终影响了数据用户的生产力,他们通常需要与多个不同的引擎交互才能完成特定的任务。这些系统中可用的数据类型、函数和聚合物各不相同,这些函数的行为、空值处理和类型转换在不同的引擎之间可能存在巨大的不一致性。例如,在Meta进行的一项非正式调查中,至少发现了12种不同的简单字符串操作函数𝑠𝑢𝑏𝑠𝑡𝑟()的实现,它们具有不同的参数语义(基于0还是1的索引)、空值处理和异常行为。
尽管专门的引擎根据定义提供了能够证明其存在的专门行为,但主要的区别通常在于语言前端(SQL、数据框架和其他DSL)、优化器、任务在工作节点之间的分配方式(也称为运行时)以及IO层。这些系统核心的执行引擎都非常相似。Velox被用在Meta内部的各个不同的引擎,虽然它们在前端语言(SQL,dataframe等),优化器,分布式任务调度等方面都不完全相同,但是在执行引擎(execution engine)层面大致相同的,都需要一个类型系统来表达scalar和complex数据类型,一个内存数据集表示(基本都是columnar,类似的有Arrow),一个表达式解析系统(expression evaluation),算子(Operator,比如joins,aggregation,sort等),以及存储和网络序列化、编码格式和资源管理原语。
Velox Structure
Type
通用类型系统,允许用户表示标量(Scalar)、复杂(Complex)和嵌套数据类型,包括struct,map,array,tensor等。Vector
Arrow-compatible列式内存布局模块,支持多种编码,包括Flat,Dictionary,Constant,Sequence/RLE, and Bias等,还支持延迟物化,乱序写入。Expression Eval
基于向量化编码(Vector-encoded)数据构建的,完全向量化的表达式求值引擎(expression evaluation engine),它借助了common subexpression elimination,constant folding,effective null propagation,encoding-aware evaluation和dictionary memoization等技术。Functions
Velox函数库提供了与流行的 SQL 方言兼容的函数包(目前,用于 Presto 和 Spark),还提供了简单(row-by-row)和向量化(batch-by-batch),聚合函数API,让开发人员构建自定义函数,库还提供了与流行SQL方言兼容的函数包(目前支持Spark和Presto)。这里论文没细说,虽然简单函数提供row-by-row的写法,最终还是向量化执行的,通过SimpleFunctionAdapter转换成向量函数,后面有空写一篇文章专门介绍。Operator
实现了常用的数据处理的算子,包括TableScan,Project,Filter,Aggregation,Exchange/Merge,OrderBy,HashJoin,MergeJoin,Unnest等。I/O
通用的connector interface,允许可插拔文件格式编码器/解码器和存储适配器。支持常见的格式,例如ORC,Parquet,以及 S3,HDFS等存储系统。Serializers
网络通信的序列化接口,可以实现不同的有线协议,支持PrestoPage和Spark的UnsafeRow 格式。Resource Management
用于处理计算资源的原语集合,例如内存区域(memory arenas),缓冲区管理(buffer managment),tasks,drivers(这里的driver指velox的pipeline的driver,非spark driver),线程池,spilling和cache。
Velox Deep Dive
Type
Velox支持标量类型和复杂类型,覆盖了基本上所有Presto和Spark的数据类型。在其核心,Velox提供了一个类型系统,允许用户表示原始类型,包括不同精度的整数和浮点数,字符串(包括varchar和varbinary类型),日期,时间戳和函数(lambdas)。它还支持复杂类型,如数组,固定大小的数组(用于实现ML张量),映射,以及行/结构;所有这些类型都可以任意嵌套,并提供序列化/反序列化方法。最后,Velox提供了一个不透明的数据类型,开发人员可以使用它来轻松包装任意的C++数据结构。
该类型系统是可扩展的,允许开发人员添加特定于引擎的类型,而无需修改主库。例如,Presto的HyperLogLog5类型用于基数估计,以及其他Presto特定的日期/时间数据类型,如带时区的时间戳。然后,可以在构建自定义标量和聚合函数时使用通过类型扩展性添加的类型。
Scalar Type
Velox中的标量类型是逻辑的并且与SQL兼容。每个标量类型都是使用C++类型实现的。下表显示了支持的标量类型及其对应的 C++ 类型。
| Velox Type | C++ Type | Bytes per Value |
|---|---|---|
| BOOLEAN | bool | 0.125 (i.e. 1 bit) |
| TINYINT | int8_t | 1 |
| SMALLINT | int16_t | 2 |
| INTEGER | int32_t | 4 |
| BIGINT | int64_t | 8 |
| DATE | struct Date | 8 |
| REAL | float | 4 |
| DOUBLE | double | 8 |
| SHORT_DECIMAL | struct UnscaledShortDecimal | 8 |
| LONG_DECIMAL | struct UnscaledLongDecimal | 16 |
| TIMESTAMP | struct Timestamp | 16 |
| INTERVAL DAY TO SECOND | struct IntervalDayTime | 8 |
| VARCHAR | struct StringView | 16 |
| VARBINARY | struct StringView | 16 |
Complex Type
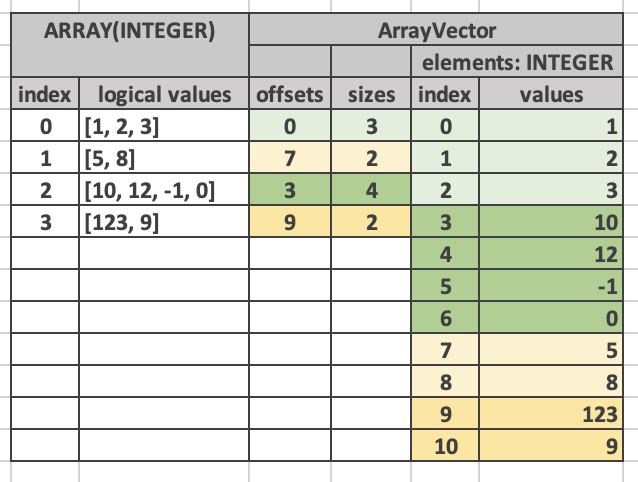
Velox还支持复杂类型,包括arrays,fixed-size arrays(用在ML tensor),maps,rows/structus;所有这些类型都可以任意嵌套并提供序列化/反序列化方法。
Vector
Velox向量允许开发者利用各种编码格式在内存中表示列式数据集,并被用作大多数其他组件的输入和输出。基本的内存布局扩展了Apache Arrow格式,由size变量(表示向量中表示的行数)、数据类型以及一个可选的空值位图组成,用于表示空值。基础向量类还提供了一系列方法,帮助用户复制、调整大小、哈希、比较和打印向量。
向量可以表示固定大小(例如,primitive types like integers
and floats)或可变大小的元素(例如,strings, arrays, maps, and
structs/rows)。
Vectors也可以以任意方式嵌套(例如,包含字符串和其他原始类型的结构的数组的数组),并可以利用不同的编码格式,如flat,
dictionary, constant, sequence/RLE, 和bias (frame of reference)。所有向量数据都使用Velox缓冲区存储,这些缓冲区是从内存池分配的连续内存片段,可以进行子类化以支持不同的所有权模式(例如,拥有和缓冲区视图)。所有向量和缓冲区都是引用计数的,一个单独的缓冲区可以被多个向量引用;自然,只有单一引用的数据是可变的,但任何向量和缓冲区都可以通过写时复制变得可写。
此外,Velox提供了Lazy Vectors的概念,这些向量只在首次使用时填充。Lazy Vectors在如连接和投影中的条件等基数减少操作中非常有用,其中,根据操作的选择性,可以完全避免物化,或将其限制在少数有效的行中。当从远程存储(如S3或HDFS)读取向量数据时,这个特性特别有用,因为它可以为稀疏访问的列优化掉整个IO操作。Lazy Vectors还提供了对加载数据运行回调的支持,这可以用于在不必物化中间向量的情况下推下计算(如聚合)。
经常的,开发者无法控制特定向量的创建方式,例如在实现标量函数或运算符时,因此需要处理可能被任意编码的输入数据。一方面,这为开发者提供了利用输入数据编码进行高效处理的灵活性(例如,只对字典编码输入的不同值进行特定操作),另一方面,这增加了复杂性,并增加了开发者的认知负担。为了解决这个问题,Velox还提供了解码向量抽象,它将任意编码的向量转换为一个flat vector和一组索引,用于所有或部分元素,并提供一个逻辑一致的API。解码向量对于Flat、常量和单级字典编码输入(最常见的情况)是零复制的,但需要实现一个新的字典索引数组来覆盖多个字典/运行长度编码的嵌套。
尽管Velox向量基于并兼容Apache Arrow格式,但Velox向量和Apache Arrow格式在三个区域有所不同:
- 字符串
Arrow使用传统的variable-sized elements布局来表示字符串,这包括一个包含字符串内容的缓冲区,以及一个表示字符串大小的长度缓冲区或一个标记字符串开始位置的偏移缓冲区,但在Velox的布局中,字符串向量也由两个缓冲区组成,一个用于元数据,每个字符串元素包含16字节,另一个用于存储字符串的数据。字符串元数据类被称为StringView,定义如下:
1 | strcut StringView { |
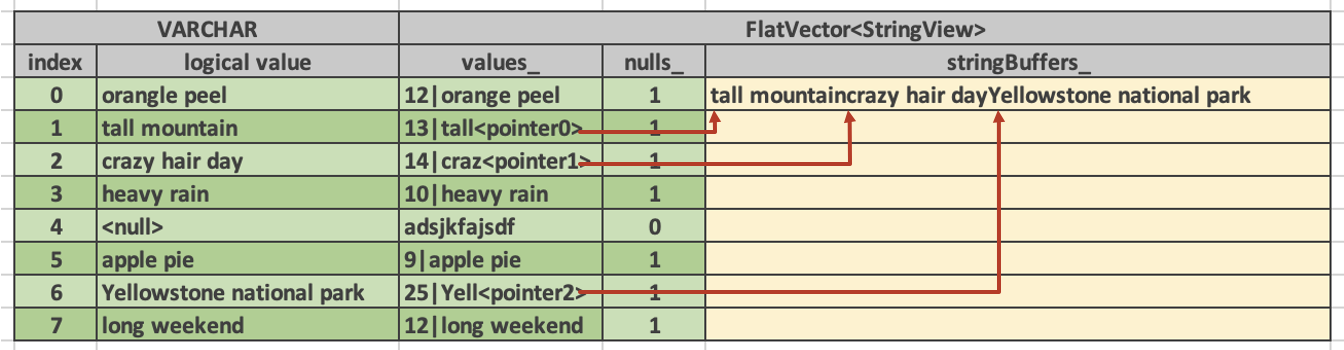
StringViews总是内联存储一个小的(4字节)前缀,专注于短路失败的比较(short-circuiting failed comparisons)以加速诸如过滤和排序等操作。此外,最大为12字节的小字符串完全内联,不需要访问次级缓冲区。这种布局还允许某些字符串操作,如𝑡𝑟𝑖𝑚()和𝑠𝑢𝑏𝑠𝑡𝑟(),通过仅更新元数据指针来执行零复制。
支持乱序写入
为了有效地支持条件语句的执行,如IF和SWITCH操作,Velox扩展了Apache Arrow格式以支持乱序写入。在这些转换中,首先求值条件(Evaluation Condition)以生成一个位掩码,描述每行应采取哪个分支。随后,基于生成的位掩码,每个分支以向量化的方式单独处理,将计算出的值写入单个输出向量。原始类型总是可以乱序写入,因为元素大小是常数。此外,使用上述表示法,字符串也可以乱序写入,因为字符串元数据对象的大小是常数(16字节)。为了支持剩余的可变大小类型(如数组和映射)的乱序写入,Velox同时维护长度和偏移缓冲区。除了加速条件语句的执行,这种布局还为引擎提供了更多的灵活性,可以在不复制的情况下切片和重新排列元素,因为每个数组/映射的长度和偏移可以独立更新,而不是允许具有重叠元素的数组/映射。更多编码
Velox向量还添加了在数据仓库工作负载中常见的两种编码格式:游程长度编码(RLE)和常量编码。后者用于表示列中的所有值都相同,例如,表示文字和分区键。
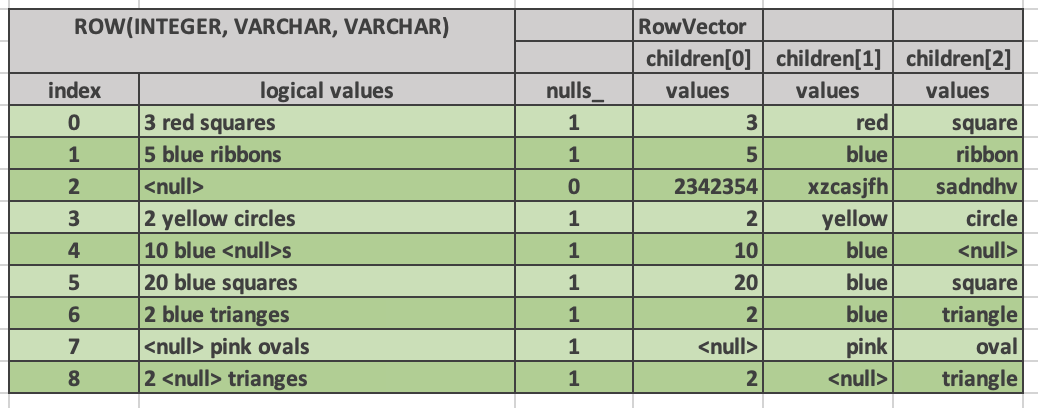
Velox vector对scalar type和complex type的物理布局本质是一样的,都包含一个value buffer连续存放实际的value,null buffer标识value是否为null,比如下面的FlatVector
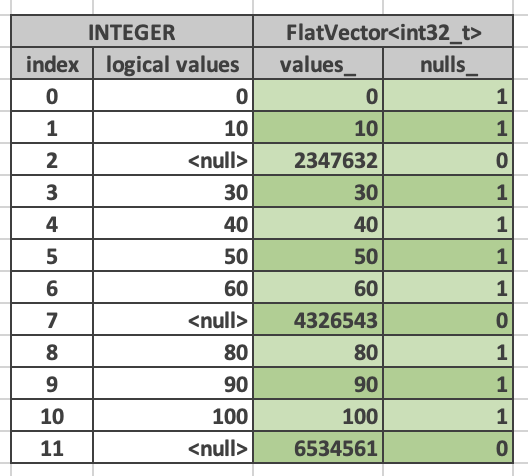 |
 |
Expression
Velox的expression evaluation引擎可以被用在3种场景:
- FilterProject算子中过滤(filter)与投影(project)的表达式求值
- TableScan算子和IO connectors一致性求值谓词下推
- 独立的组件给只需要表达式求值功能的引擎,比如实时计算,ML场景的数据预处理
表达式求值的输入表达式树,有以下几种节点:
- a reference to an input column,代表一个input RowVector的列(比如,C0),必定是叶子节点
- a constant (or literal),必定是叶子节点
- a function call,比如array_has_duplicates, hmac_sha256,还有类似AND/OR,IF/SWITCH,try这样的
- a CAST expression
- a lambda function,比
(x, y) -> x + y
表达式树节点还包含以下两类元数据
- 子表达式是否具有确定性,即相同的输入产出相同的结果
- null传播,任何一个输入列的value为null是否总是让该表达式结果为null
Expression Trees
表达式求值以表达式树作为输入。树中的每个节点都是core::ITypedExpr的子类,它指定了返回类型和零个或多个输入表达式(树中的子节点)。每个表达式可以是以下之一:
- FieldAccessTypedExpr(字段访问表达式)
- ConstantTypedExpr(常量表达式)
- CallTypedExpr(函数调用表达式)
- CastTypedExpr(类型转换表达式)
- LambdaTypedExpr(Lambda表达式)
FieldAccessTypedExpr表示输入RowVector的一列。该列由名称标识。这始终是树中的叶节点。
ConstantTypedExpr表示一个常量值(或字面值)。这始终是树中的叶节点。
CallTypedExpr表示一个函数调用。函数由名称标识。输入表达式指定函数的参数数量和类型,从而可以明确地识别特定的函数实现。该函数可以是简单函数或矢量化函数。
CallTypedExpr还可以通过指定预定义名称来表示特殊形式。这些名称不能被简单函数或矢量函数使用。
Compilation
将expression tree作为输入,编译成可执行的expression(Compiled Expression / Executable Expression)
- 表达式消除(Common Subexpression Elimination)
比如strpos(upper (a), ‘FOO’) > 0 OR strpos(upper(a), ‘BAR’) > 0中的upper(a)只计算一次即可 - 常量折叠(Constant Folding)
比如upper(a) > upper(‘Foo’)中upper(‘Foo’)是确定的,不依赖任何输入列,可以直接转成‘FOO’ - 自适应重排(Adaptive Conjunct Reordering)
在求值AND或OR表达式时,引擎动态跟踪各个合取式的性能,并选择先评估最有效的合取式,即在最短时间内丢弃最多值的合取式,按照𝑡𝑖𝑚𝑒/(1 + 𝑛_𝑖𝑛 − 𝑛_𝑜𝑢𝑡)计算得分,得分越低越好。为了在执行过程中最大化自适应合取式重排序的效果,表达式编译还会将相邻的AND/OR表达式展平。例如,输入表达式AND(AND(AND(a, b), c), AND(d, e))在编译过程中被展平为单个AND(a, b, c, d, e)节点。
要编译一个表达式,需要创建一个exec::ExprSet的实例。ExprSet的构造函数接受一个表达式列表(core::ITypedExpr指向表达式树的根节点)和一个上下文(core::ExecCtx)。构造函数处理这些表达式,并创建exec::Expr类实例的树。ExprSet接受多个表达式,并识别出所有表达式中的公共子表达式,以便可以只计算一次。FilterProject运算符受益于这种能力,因为它为所有的过滤和投影表达式创建一个单独的ExprSet。编译步骤还会展开相邻的AND、OR和concat-line表达式,并执行常量折叠。表达式树中的每个节点都被转换为exec::Expr类的相应实例。
| core::ITypedExpr node | exec::Expr instance |
|---|---|
| FieldAccessTypedExpr | FieldReference |
| ConstantTypedExpr | ConstantExpr |
| CallTypedExpr | - CastExpr if function name is “cast”; - ConjunctExpr if function name is “and” or “or”; - SwitchExpr if function name is “if” or “switch”; - CoalesceExpr if function name is “coalesce” - TryExpr if function name is “try”; - Expr if function name is none of the above. |
| CastTypedExpr | CastExpr |
| LambdaTypedExpr | LambdaExpr |
CallTypedExpr节点被处理以确定函数名称是否指向特殊形式表达式或函数(矢量化或简单函数)。查找按照以下顺序进行,并在第一个匹配时停止搜索:
- 检查名称是否与
special forms之一匹配 - 检查名称和签名(即输入类型)是否与向量化函数之一匹配
- 检查名称和签名(即输入类型)是否与简单函数之一匹配
Evaluation
求值过程接受一个编译的表达式和一个输入数据集(使用Velox向量表示),在计算结果后返回一个输出数据集。该过程包括对表达式树进行递归下降,传递一个行掩码,用于标识活动的(非空且未被条件掩码屏蔽)元素。在每个步骤中,可以避免评估两种情况:
- 如果当前节点是一个常见的子表达式并且结果已经计算过(Common Subexpression Elimination)
- 如果表达式被标记为传播空值,并且其任何输入为空。后一步可以通过简单地组合所有输入的空值位掩码并使用SIMD操作更新活动行掩码来高效实现(nulls propagation)
Peeling(剥离):当输入是字典编码时,可以通过仅考虑不同的值来高效计算确定性表达式。首先,需要验证所有输入列是否共享相同的字典封装,如果是,则剥离这些封装以提取内部向量集合(不同的值),在这些内部向量上评估表达式,并使用原始封装将结果重新封装回字典向量。例如,考虑一个使用字典编码的向量,表示颜色列的1k行数据集,使用包含3个值的字典进行编码:0 - red, 1 - green, 2 - blue。内存布局包括一个包含1k个值的索引缓冲区,范围为[0, 2],以及一个大小为3的内部向量,包含以下值:[red, green, blue]。例如,在评估表达式𝑢𝑝𝑝𝑒𝑟(𝑐𝑜𝑙𝑜𝑟)时,剥离字典封装后,upper函数仅应用于3个不同的值 - [红色,绿色,蓝色] - 生成另一个大小为3的向量:[RED,GREEN,BLUE]。作为最后一步,使用原始索引将结果封装为字典向量,生成一个表示1k个大写颜色值的字典编码向量。
Memoization(记忆化):评估步骤可以根据需要重复执行,以处理多个批次的数据,并重用相同的编译表达式对象。例如,当从TableScan运算符读取多个数据批次时,批次通常是字典编码的,并引用相同的基础向量。在上述描述的示例中,颜色列可能有数百万行引用相同的不同值基础集合[red, green, blue],由具有相同基础向量但不同索引缓冲区的字典编码向量表示。评估引擎利用这个特性,并记住在基础内部向量上计算的表达式评估结果,以便在后续批次中重用这些结果。对于每个新的批次,它只需使用输入向量的索引缓冲区包装现有的计算结果。
总之,对于简单的原始类型的算术操作,所描述的许多技术可能并不会带来显著的改进,但对于复杂的表达式,如字符串操作、正则表达式、数组/映射操作以及其他嵌套数据类型的操作,它们确实提供了显著的加速。Velox在优化这些工作负载时做出了明智的决策,考虑到实证数据表明这些操作是CPU时间消耗最高的,同时为基本情况提供了快速路径。
将可执行的expression和input dataset计算结果,返回output dataset。这个过程包括递归下降处理expression tree,向下传递一个行掩码(row mask)标识有效的行。每个步骤都会避免重复计算
- common subexpression
- nulls传递expression,且有输入为null
Velox的开发者文档对Expression的优化描述更详细,可以对照看一下。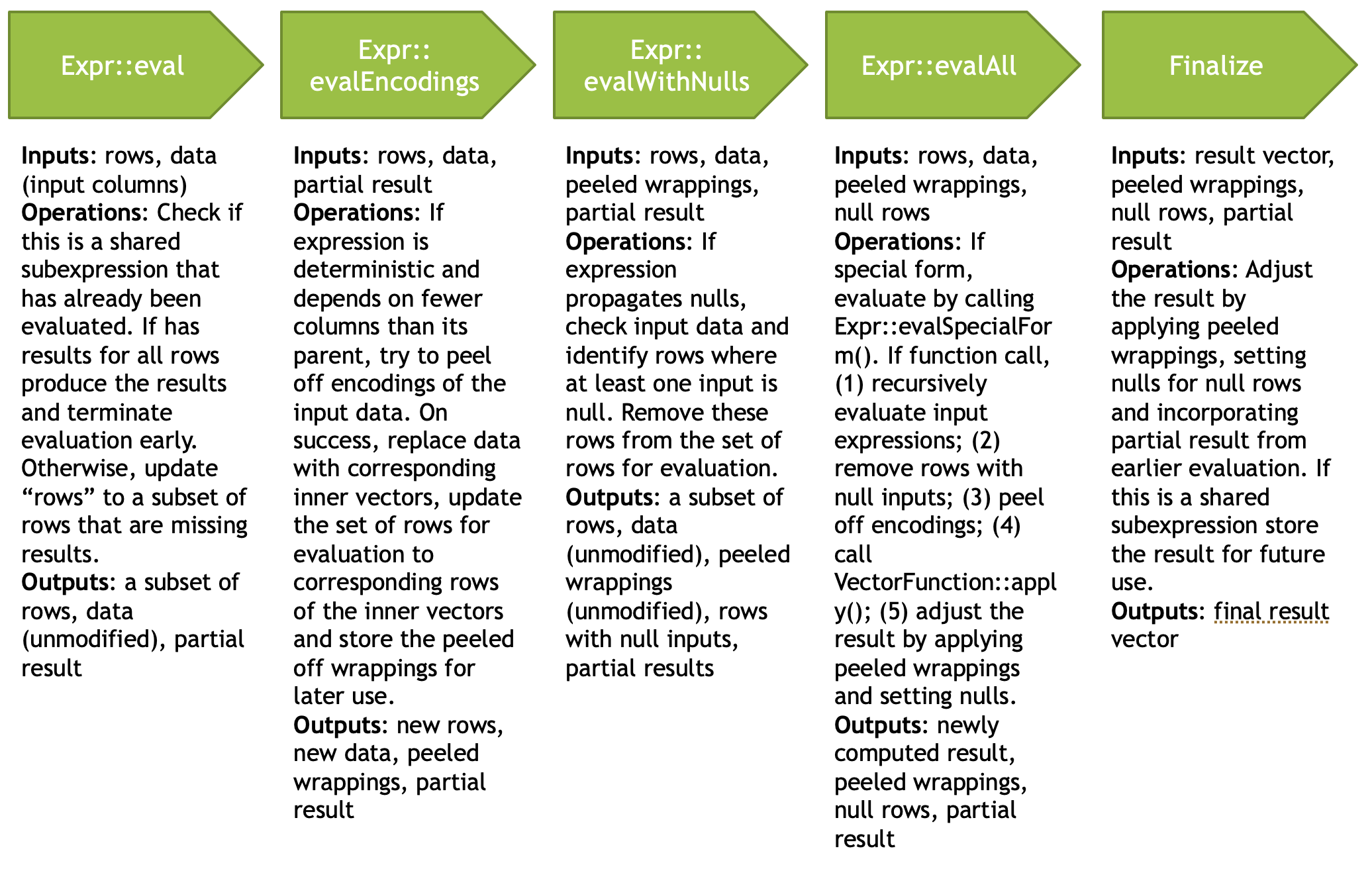
Code Generation
Velox还提供了对通过代码生成(codegen)进行表达式求值的实验性支持。启用时,执行时将整个表达式树重写为C++函数的源代码,并将其写入源文件,使用常规编译器(如gcc或clang)将其编译为共享库。然后,将共享库动态链接到主进程,并在求值时使用它,而不是使用向量化的解释路径。考虑到代码生成过程涉及完整的编译器调用,编译时间通常很长(在某些情况下长达10秒),并且不适用于短期查询或交互式工作负载。相反,我们最初的评估重点是大型ETL查询(执行时间为几小时到几天),以及表达式树固定的用例。截至目前,Velox中的代码生成支持仍处于实验阶段。权衡编译延迟、降低开发人员生产力和可调试性,以及在向量化和基于代码生成的评估路径之间探索运行时适应性的工作是未来研究的开放问题和方向。
Function
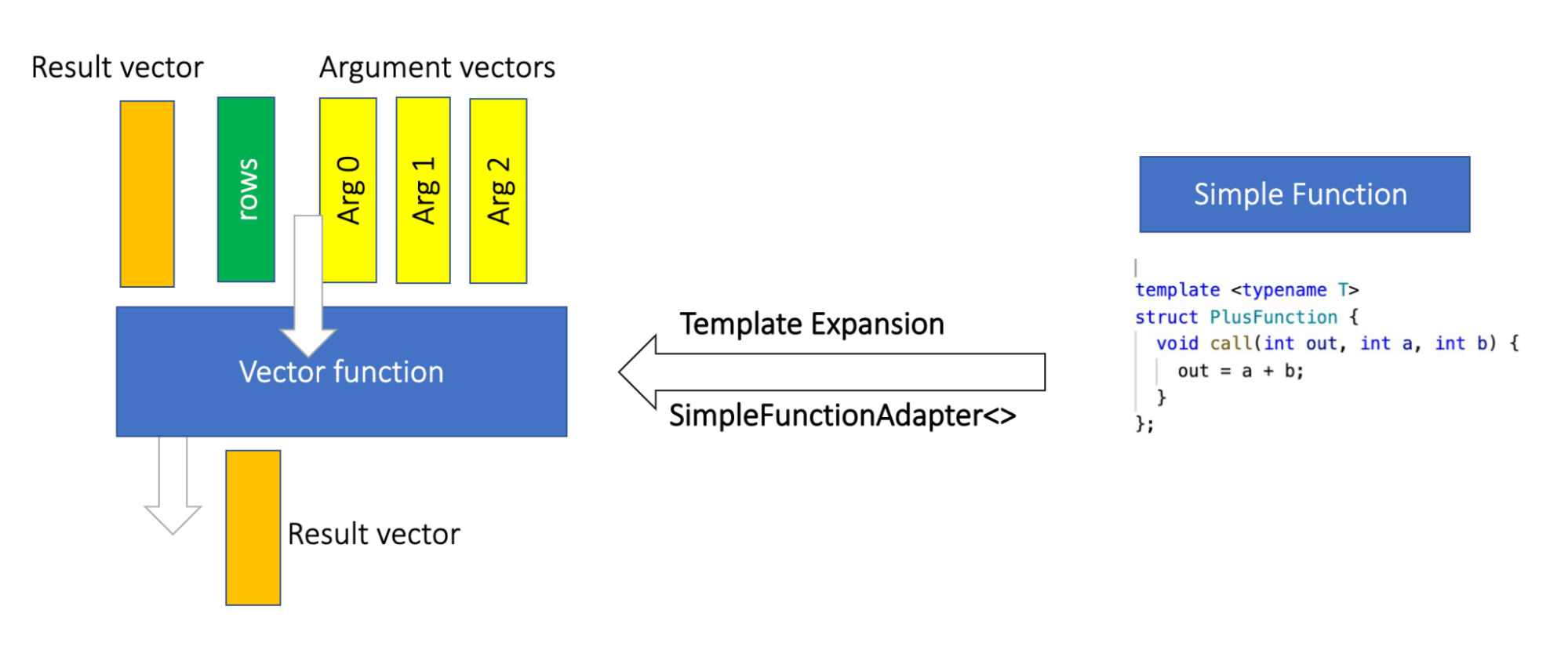
Velox提供了API让开发者定制(主要是velox社区实现各类prestosql或者sparksql的functions,aggregate functions),scalar functions和aggregate functions。作为一个向量化引擎,Velox的scalar function API可以是向量化的,即输入参数是batch-by-batch的vectors,还包括 nullability buffers,active rows(bitmap),并可以利用vectors内置的null buffer,length buffer和key buffer等实现常量时间复杂度的is_null(), cardinality()和keys()等操作。
Velox还提供了一个Simple Function Framework,让开发者只需要用传统的按行处理的scalar function的方式开发,框架会利用元编程,编译器hint方式等转成向量化实现。该框架不仅屏蔽了vector解码的细节,还直接映射了所有的primitive类型到对应的C++类型,对于一些非primitive类型,比如std::string, std::vector则是通过代理对象和ArrayReader/ArrayWriter这样的API直接操作vector的底层数据,而不做额外的allocation或者拷贝。此外对字符串的处理,velox提供了ASCII-only这样的fast path来加速,详细可以看这个官方博客。
Operators
Velox查询计划由一棵PlanNode树组成,例如Filter、Project、TableScan、Aggregation、HashJoin、Exchange等,描述了要执行的计算过程。为了执行查询计划,计划节点首先被转换为运算符(Operator)。转换通常是一对一的,但也有一些例外,例如(a)Filter节点后跟Project节点被合并为单个FilterProject运算符,以及(b)具有两个或多个子节点的计划节点被转换为多个运算符,例如,HashJoin节点被转换为一对运算符,HashProbe和HashBuild,详细转换参见这里。。
Velox的顶层执行概念是Task,它是分布式执行中的函数传输单元,对应于查询计划片段以及其运算符树。任务以TableScan或Exchange(shuffle)源作为输入开始,并以另一个Exchange结束。任务的运算符树被分解为一个或多个线性子树,称为Pipeline:例如,HashProbe和HashBuild分别映射到一个Pipeline。每个Pipeline具有一个或多个执行线程,称为Driver,每个Driver都有自己的状态。Driver可以在线程上运行或不运行,这取决于它们是否有工作要执行。Driver之所以可能让出线程,有很多原因,例如,因为其消费者尚未消费数据,其源Exhange尚未产生数据,或者Scan正在等待文件扫描。与传统的Volcano迭代器树模型相比,这种模型更方便进行线程上下文切换,因为状态是可恢复的,无需在堆栈上构建控制流。最后,任务可以随时被其他Velox执行器取消或暂停。能够暂停任务在强制执行优先级、检查点状态、强制另一个任务溢出或其他协调活动的情况下非常方便。
所有运算符实现了相同的基本API,包括添加一批向量作为输入、获取一批向量作为输出、检查运算符是否准备好接受更多输入数据以及通知不再添加数据的方法;后者可以用于通知阻塞排序或聚合刷新其内部状态并开始生成输出。尽管Velox已经提供了一套广泛使用的运算符,但该库还允许引擎开发人员添加包含特定于引擎的业务逻辑的自定义运算符,例如基于流的流处理聚合。
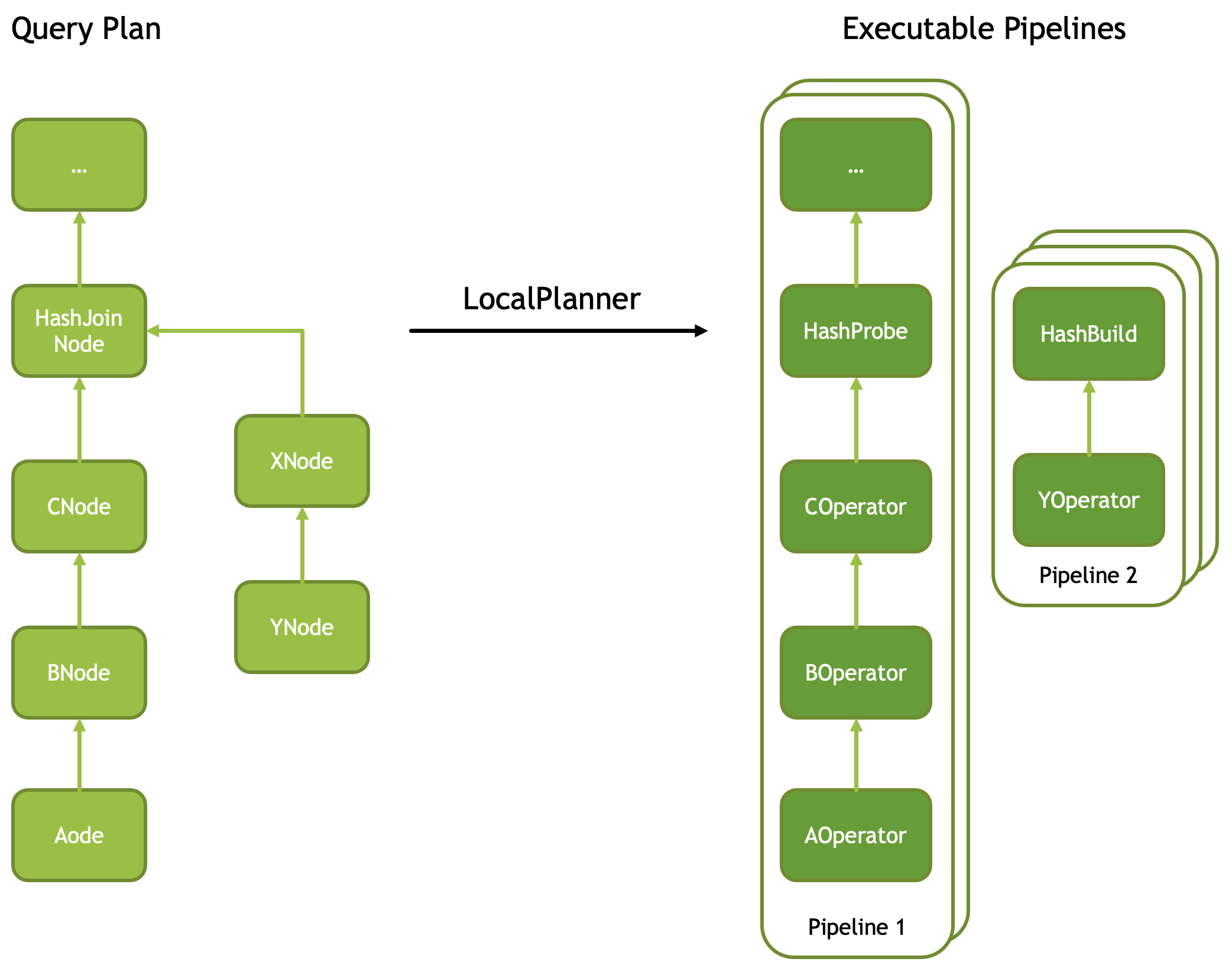
Table Scans, Filter, and Project
表扫描是按列进行的,并支持过滤器下推。首先处理包含Filters的列,生成命中的行号以及可选的命中值。过滤器在运行时自适应排序,以便首先评估最小时间丢弃值的过滤器。得分定义为𝑡𝑖𝑚𝑒/(1 + 𝑛_𝑖𝑛 − 𝑛_𝑜𝑢𝑡),以使最优Filter在最短时间内丢弃最多的值。这与在前面的AND/OR表达式中重新排序连接词的原理相同。
简单过滤器使用SIMD一次评估多个值,这使得Velox能够使用AVX2在每个CPU时钟大约处理一个整数命中。对于字典编码的数据,Filters结果被缓存,并再次使用SIMD来使用gather + compare + mask lookup + permute检查缓存命中,以写出通过的行,平均每个CPU时钟处理多个命中。Velox还为大型IN Filters提供了高效的实现,用于哈希连接下推,它可以一次触发4个缓存未命中(4 * 64 = 256 = avx2_regsiter_width)。
此外,FilterProject运算符对于所有filter和project表达式使用单个表达式evaluate context。对于每批输入数据,运算符首先在所有输入行上计算filter表达式,然后仅对通过filter的行子集执行project表达式。如果没有行通过filter,将完全跳过project表达式的求值。
Aggregate and Hash Joins
哈希连接和聚合是分析数据处理的基础。Velox提供了一个精心设计的哈希表实现,针对这两种用例进行了优化,除了促进可重用性,还统一了这两种场景中的适应性。哈希键以列的方式处理,使用一个称为VectorHasher的抽象,它识别键的范围和基数,并在适用的地方将键转换为一个较小的整数域。如果所有的键都映射到少数的整数,那么它们直接映射到一个flat array。如果有多个键,它们会尽可能地映射到一个单一的64位规范化的键,并且根据这个生成的键的范围,要么用来索引一个flat array,要么用作一个单一的哈希表键。只有在上述所有优化都不可能的情况下,才会使用效率低下的多部分哈希键。此外,最优的哈希布局是自适应决定的,并且随着新批次数据的处理而可能改变。考虑到VectorHashers形成了每个键的不同值的一种摘要,这些对象也可以被推下到TableScans,并作为有效的IN Filter,在表扫描和哈希连接位于同一位置的情况下使用(Join Filter下推)。不同键的查找之间的内存访问是交错的,目的是最大化在一段时间内的缓存未命中的数量,并由于数据依赖性而导致更少和更短的管道停滞。哈希表的值以行的方式存储,以最小化缓存未命中,因为在哈希连接和聚合中通常访问所有依赖的数据。
Memory Management
Velox任务通过内存池来跟踪内存使用情况。像查询计划、表达式树和其他控制结构这样的小对象直接从C++堆中分配,但像数据缓存条目、用于聚合和哈希连接的哈希表以及其他各种缓冲区这样的大对象则使用自定义分配器分配,该分配器为大对象提供零碎片化(使用mmap和madvise)。所有通过内存池进行的内存分配都以分层方式进行跟踪,并受到限制执行策略的约束。Velox内存消费者也可以预留内存,以便有一个保证的预算来完成特定的操作,如处理一批group by键。内存消费者可能提供恢复机制,如在内存分配失败时进行溢出。为了支持内存恢复策略,消费者可能会被异步暂停;当请求暂停时,消费者将通过离线并返回一个continuation future,允许引擎在稍后的时间点恢复消费者的执行。在暂停状态下,任务可能被指示溢出到二级存储,或者被取消以为其他任务腾出空间,这取决于优先级策略。 超过内存限制的默认行动是调用一个进程范围的内存仲裁器。这个仲裁器可以看到所有正在运行的任务、它们的内存使用情况以及可回收的内存量,这是任务在被指示溢出的情况下可以释放的内存量。然而,决定哪个任务将被要求溢出或被取消的逻辑是可插入的,可以由开发者提供,以实现引擎特定的行为。 为了支持溢出,operators需要实现一个接口,该接口说明通过溢出可以释放多少内存,以及实际的溢出方法。如果这些方法没有被operators实现,当分配失败时,operators别无选择,只能在没有额外分配的情况下继续执行,或者失败。最后,操作员也可以选择监控整体内存使用情况,并根据不同的内存压力情况做出反应;例如,Exchange operator可以决定在内存变得稀缺(或者其分配失败)时减少其缓冲区大小。
Caching
对于利用存储计算分离架构的数据计算系统,Velox为内存和SSD缓存提供支持,以减轻远程IO停滞对查询延迟的影响。内存缓存充当特殊的内存用户,并被允许消耗所有未分配的内存。所有IO缓冲区都直接从内存缓存中分配,并可以根据底层列式数据集的布局有任意大小,这与操作系统中缓存以固定大小的块(页面)分配不同。通过利用mmap/madvise,可以混合任意分配大小而不产生碎片。
首先从分散的存储系统(如S3或HDFS)读取缓存的列,存储在RAM中以供首次使用,并最终持久化到本地SSD。此外,如果它们之间的间隙足够小(目前对于SSD约为20K,对于分散存储约为500K),通常会合并附近列的IO读取,以尽可能少的IO读取来服务邻近的读取。自然地,这利用了时间局部性的效果,使相关的列在SSD上一起缓存。
考虑到所有远程列式格式都有类似的访问模式,首先读取文件元数据以确定缓冲区边界,然后读取这些缓冲区的部分,IO读取可以提前安排(预取)以交错IO停滞和CPU处理。Velox跟踪每个查询基础上的列访问频率,并为热列自适应地安排预取。内存缓存和智能预取逻辑的结合使许多基于小到中等大小表的SQL交互式分析工作负载能够有效地从内存中服务,因为IO停滞已经从关键路径中移除,不再对查询延迟产生影响。
下表展示了从存储层次结构的不同层次读取的吞吐量(读取延迟,加上解码和解压缩)。根据Meta硬件和工作负载的实证数据,RAM缓存命中大约比从本地SSD读取快3倍,而从Meta的分散存储系统远程读取则大约快4倍。这些数据对应于在基于26核服务器(具有64GB内存和2x2TB SSD设备)上执行简单过滤或聚合的标量列的查询。
| RAM | SSD | Disaggregated | |
|---|---|---|---|
| Read rate | 8GB/s | 2-3GB/s | 700MB/s |
EXPERIMENTAL RESULTS
使用Prestissimo进行端到端测试所获得的实验结果,将新的基于C++的Velox执行引擎与当前的Presto Java实现进行了比较。测试平台是一个由80个节点组成的集群,每个节点有64G RAM和2x2TB SSD设备。两个系统都启用了本地缓存,并从热缓存运行。数据集是一个3TB的TPC-H,以ORC格式存储,没有zstd压缩,lineitem和orders共同分区。查询公式是手写的,以便具有正确的连接树形状,所有选择性连接都集中在构建侧,连接是哈希连接。表2展示了选定的CPU绑定查询(Q1和Q6)以及shuffle/IO重型查询(Q13和Q19)的CPU和wall time。对于CPU bound的查询,Q1和Q6,Prestissimo提供了接近一个数量级的加速,现在的瓶颈是协调器分派工作的速度。对于那些shuffle数据的查询,Q13和Q19,新的瓶颈是shuffle延迟。可能的优化是在协调器上更好地处理元数据,更好地调整和消息大小在shuffle上,可能还有一些非常轻量级的编码以减少shuffle数据量。
| Wall time (sec) | Wall time (sec) | |||||
|---|---|---|---|---|---|---|
| C++ | Java | Speedup | C++ | Java | Speedup | |
| Q1 | 5 | 42 | 8.4x | 2211 | 14335 | 6.5x |
| Q6 | 1 | 9 | 9x | 538 | 2018 | 6.5x |
| Q13 | 15 | 31 | 2x | 5647 | 12322 | 6.5x |
| Q9 | 6 | 13 | 2.1x | 1362 | 3483 | 6.5x |
虽然TPC-H仍然是系统比较的有效数据点,但它并不能全面代表现代工作负载。为了评估Velox在实际工作负载下的性能,在Meta中找到的各种交互式分析工具生成的生产流量重播到两个具有相同硬件特性的集群(一个运行Prestissimo,一个运行Presto Java)。Prestissimo相对于Presto Java提供的相对加速的平均加速约为6-7倍,但许多查询观察到的加速超过一个数量级。
最后,除了最初的问题,即新的基于C++的堆栈可以节省多少CPU之外,当处理超大规模系统部署时,一个自然的后续问题是这个新堆栈在服务器数量方面的容量影响,这最终转化为数据中心的电力。为了进行这个实验,创建了两个集群(一个Prestissimo和一个Presto Java),它们完全复制了相同的生产工作负载,并慢慢减少了Prestissimo集群中的服务器数量。我们观察到,使用基于Velox的堆栈,Prestissimo能够以相等或更好的用户感知性能支持相同的工作负载,但服务器数量减少了3倍(从60减少到20)。
参考
- https://engineering.fb.com/2022/08/31/open-source/velox/
- https://vldb.org/pvldb/vol15/p3372-pedreira.pdf
- https://velox-lib.io/blog
- https://facebookincubator.github.io/velox/develop.html
- https://arrow.apache.org/
- https://db.in.tum.de/~leis/papers/adaptiveexecution.pdf
- https://engineering.fb.com/2019/04/25/developer-tools/f14/
- https://db.in.tum.de/~freitag/papers/p29-neumann-cidr20.pdf